- 会員限定
- 2021/08/16 掲載
AIの「画像・音声・動画認識」のカラクリ、機械学習のプロセスを解説
連載:図でわかる3分間AIキソ講座
機械学習の進歩によって画像認識や音声認識のツールが当たり前のように使われるようになりました。しかし、その仕組みをきちんと理解して利用している人は少ないのではないでしょうか。今回は、画像認識や音声認識のAI(人工知能)がどのように作られているのかを簡単に解説していきます。
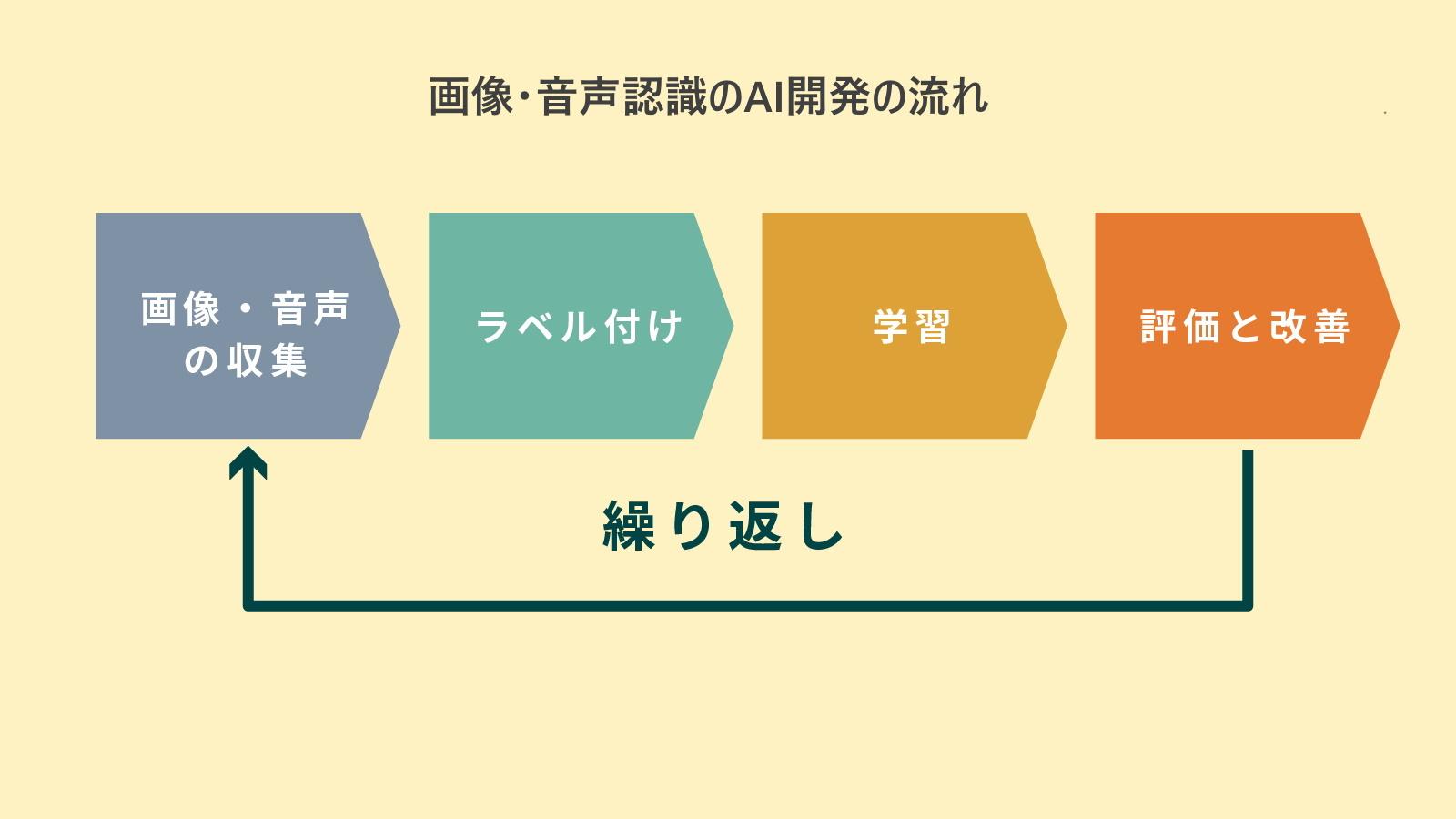
画像・音声認識のAI、開発の流れとは
画像や音声をベースにしたAIが作られる際のプロセスは、基本的に下記ようになります。- 「データを集める」
- 「正解となるラベルを付ける」
- 「学習させる」
- 「学習の成果を評価して改善する」
この流れは多かれ少なかれAIが完成した後も続けられます。ここからは、それぞれのプロセスを簡単に解説していきます。
(1)データを集める
「画像・音声データの収集」は、学習用データを集めるプロセスです。基本的に画像や音声認識に用いる機械学習プロセスでは膨大な量の学習データが必要になるため、このプロセスの自動化は必要不可欠なものとなります。このプロセスを効率的に行うために学習用データを集めるツールやプログラムが作られ、それ自体が自律的に動作するAIのような機能を持っている場合もあるほどです。
人間による手作業でデータ収集・生成される場合でも、不特定多数の人間が参加できる工夫がなされていたり、人間の自然な情報活動の中でデータが作成されるようになっていたりする場合が多いです。SNSなどにアップロードされる画像・音声データがその好例でしょう。
また、購買データのようにすでにデータが集まっているという場合には、学習に使うデータの分類と整理が行われます。
(2)ラベルを付ける
「ラベル付け」の作業は場合によっては人間による手作業が多く含まれるプロセスです。この「ラベル」とは、いわゆる「教師データ」にあたるもので、そのデータが「何」なのか、画像・音声としてどんな「答え」が正しいのか、といった情報をデータに付与します。
SNSなどでよく使われる「タグ」のような形でデータの収集段階で簡易のラベルが付くこともありますが、質の良い学習データを作る際には人間によるチェックが必要不可欠です。
また、高度な画像・音声認識AIになるほど、このラベル付けが難しくなります。動物の画像など、誰でも知っているようなモノに関するラベル付けであれば誰でもできますが、医療画像のラベル付けは「医師」や「検査技師」にしかできないなど、専門知識が要求されます。
また、膨大なデータに1つひとつラベルを付けていかなければならないのでコストのかかる作業になります。そのため、ラベル付けそのものが少なくても学習できるような研究開発が進んでいます。
(3)学習させる
次に「学習」です。実はこの学習プロセスが人間にとっては一番簡単です。というのも、この前の段階で学習用のアルゴリズムやプログラムは完成しているので、学習時にはデータを流し込むだけだからです。学習方法は機械学習の手法にもよりますが、データを用いた学習自体は自動的に行われます。この学習に使うデータは「ラベル付き」だけに限らず、学習方法によっては「ラベルなし」のものや「ハズレのデータ」がノイズとして混ぜられることがあります。学習時に「ランダムなノイズ」を混ぜることは意外と重要で、過学習と呼ばれる学習のさせ過ぎで起こる不具合を防ぎ、学習効率を向上させる効果があります。
このプロセスで人間がやることは少ないものの、1つひとつのデータが大きい「気象」「天体」「交通」などの画像データを扱う場合には学習そのものに時間がかかることもあります。場合によってはスーパーコンピューターを使って学習することもあります。
(4)学習の成果を評価・改善する
最後に「評価と改善」です。これは実際にAIを使ってみて問題点をあぶり出し、プログラムやデータを修正したり、新しくデータを集め直したりと、次につなげていくプロセスとなります。学習が終わったプログラムを「使う」のは簡単です。ただ、それによって得られた結果を評価して改善することが難しく、評価によって問題の「原因」を見つけ出し「解決策」を考え、実際に改善するための「行動」をするまでにかなりのコストがかかります。
このプロセスも人間が手動で行うことになります。一方で、AIによって「評価と改善」を自動化する試みも進んでいます。しかし、その場合にも「評価改善自動化システム」の評価と改善を人間が行うことになるので、AI開発ではどこかに必ず人間の手が入るというのが現状です。
【次ページ】「画像・音声認識」の発展形、動画認識の仕組みとは
関連コンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
関連コンテンツ
あなたの投稿
PR
PR
PR
