- 会員限定
- 2023/11/17 掲載
RLHF(人間による評価を利用した強化学習)とは?ファインチューニングとの違いも解説
近年、ChatGPTのような「大規模言語モデル(LLM)」が大きな注目を浴びています。全世界で多様な規模や特性を持つLLMが次々と開発されており、中にはChatGPTよりも小さな規模ながら、それに匹敵する性能を持つものも現れています。LLMの性能差を生み出す要因は多々ありますが、「学習方法」も非常に重要な役割を果たしています。本記事ではこの学習方法について、ChatGPTで大きな性能を発揮した「RLHF(Reinforcement Learning from Human Feedback:人間による評価を利用した強化学習)」という技術について解説します。

「RLHF」とは? ChatGPTで注目された学習法
RLHF(Reinforcement Learning from Human Feedback:人間による評価を利用した強化学習)とは、端的に言えば、人間から学ぶ「教師あり学習」と試行錯誤を経て学ぶ「強化学習」、強化学習に欠かせない報酬を学ぶ「逆強化学習」の3つの学習を組み合わせた手法です。これにより、人間の関与を最小限に抑えつつ、評価方針がはっきりしない難解なタスクをAIに学習させることができます。「教師あり学習」は人間が正解を与える機械学習で、答えが分かっている場合に使いますが、教師あり学習の課題は「正解が分からない場合は使えない」という点と「答えを出す方法を教えられない」という点にあります。そのため、基本的には答えが出るまで学習させる強引な学習になってしまい、時間がかかる割には過学習などで使い物にならないような結果に陥ることがあります。
それに対して「強化学習」は報酬を求めて最適な行動を探していくための機械学習方法で、報酬を用いて「行動を目標に向かって誘導していくことができる」という点で大きなメリットがあります。正解が分からなくとも「大まかな目標が分かれば使える」という点が強みでしたが、問題は目標に近づくための「報酬設定」が難しく、報酬の種類が無数に増えてしまうことがある点が欠点でした。
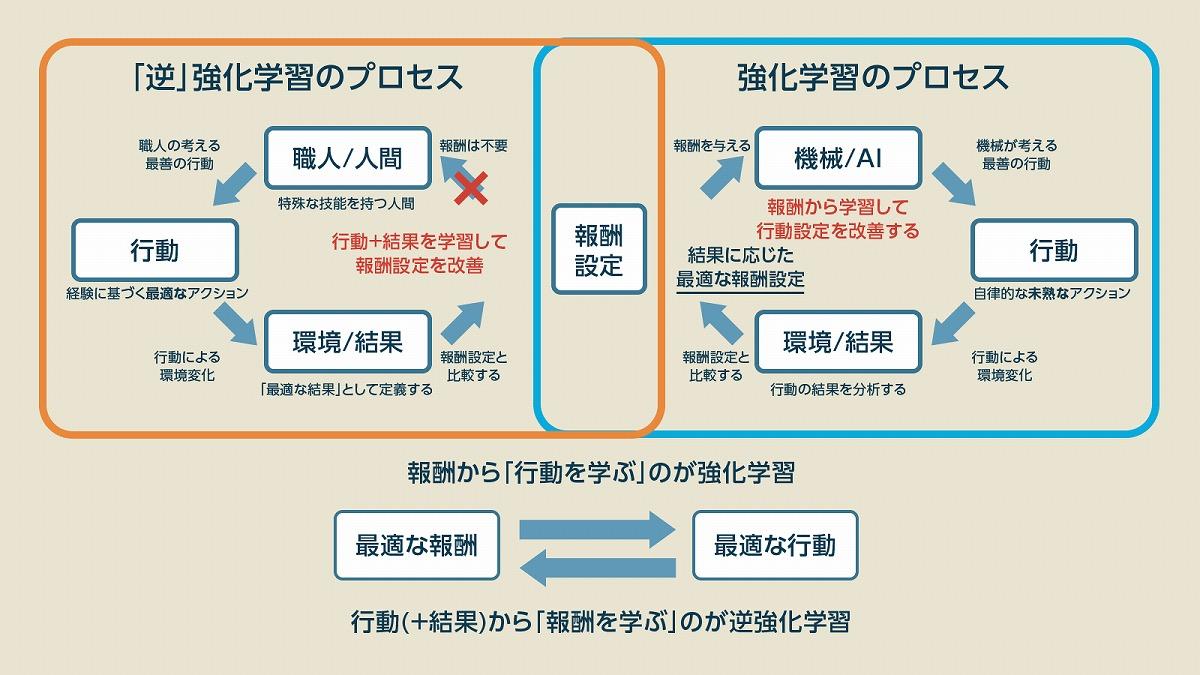
(出典:筆者作成)
この問題点を補完するのが「逆強化学習」です。こちらは「最適な行動」から「最適な報酬」を見つけるための機械学習のことで「正しい報酬」は分からなくとも、目標となる「職人や専門家の行う正しい行動」が分かっていれば、正しい行動に近づけるための報酬設定は計算できるはず、という理屈です。いわば、プロの行動を観察しながら「どのような報酬を設定すれば同じ行動に近づくだろうか」というのを考えるのが逆強化学習というわけです。
関連用語「ファインチューニング」との違い
RLHFに関連して、必ず触れられる学習法が「ファインチューニング(Fine-Tuning)」です。これは事前学習済みの学習モデルに対して、特定のタスクに特化させた訓練を行う「目的特化型の機械学習」のことで、AIモデルの応用事例には必ずと言って良いほどよく出てくる用語です。事前学習の際に「基礎知識」的な学習は終わっているので、ファインチューニングではタスクに合わせたニューラルネットワークの重み付けの微調整(チューニング)を行います。この際、ベースの部分は完成しているので大きな修正は不要となるため、劣化を防ぎつつ、手軽に性能を向上させることができます。
このことからも分かるように、ファインチューニングというのは「特定の学習方法」を指す言葉ではなく「特定の目的をもって行う学習」だということです。このため、RLHFもある意味では「ファインチューニング」としての役割も持っています。
ChatGPTでは、RLHFを行う前に人間による「チャットの会話例」を正解データとした「教師あり学習」を用いた「ファインチューニング」を行っており、RLHFとは明確に区別しています。しかし、開発事例の中には「RLHFの要素を取り入れたファインチューニング」のように、両者を混ぜて語ることも少なくありません。
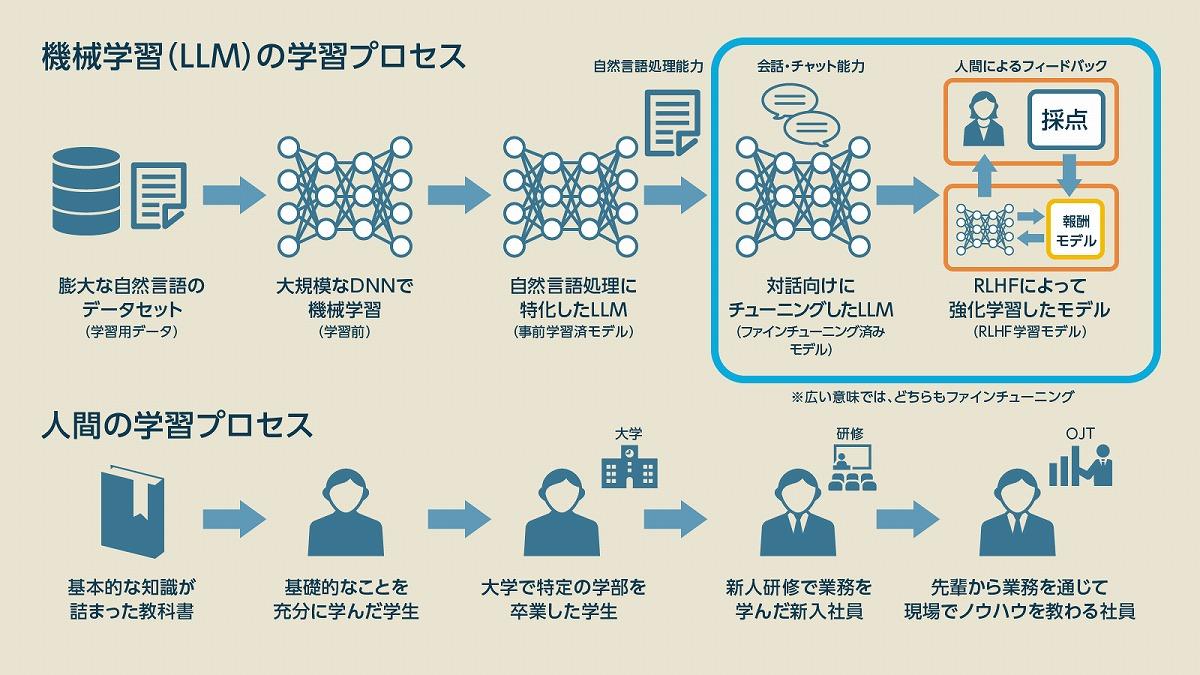
(出典:筆者作成)
RLHFが学習の「手法」を指す言葉なのに対して、ファインチューニングは学習の「目的や段階」に応じて使われる言葉だと理解しておくと良いでしょう。人間に例えるなら、ファインチューニングというのは「入社後の研修」のようなもので、RLHFは「先輩からフィードバックを受けながら働くOJT」といったところでしょうか。 【次ページ】ChatGPTはどう作られてる? RLHFに加えた”ある改良”とは
関連コンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
関連コンテンツ
あなたの投稿
PR
PR
PR
