- 会員限定
- 2024/01/15 掲載
Transformerとは何か? 「ChatGPT」や「Gemini」を生み出した超重要技術の進化
合同会社Noteip代表。ライター。米国の大学でコンピューターサイエンスを専攻し、卒業後は国内の一部上場企業でIT関連製品の企画・マーケティングなどに従事。退職後はライターとして書籍や記事の執筆、WEBコンテンツの制作に関わっている。人工知能の他に科学・IT・軍事・医療関連のトピックを扱っており、研究機関・大学における研究支援活動も行っている。著書『近未来のコア・テクノロジー(翔泳社)』『図解これだけは知っておきたいAIビジネス入門(成美堂)』、執筆協力『マンガでわかる人工知能(池田書店)』など。

(Photo/Shutterstock.com)
Transformerとは?
Transformerとは、グーグルで開発されたディープラーニング(深層学習)のアーキテクチャのことです。後述するTransformerの発展型となる「Vision Transformer(ViT)」「Unified Transformer(UniT)」「Decision Transformer(DT)」「Robotics Transformer(RT)」などのベースの技術となっており、発展型を含めてTransformer系の技術は、自然言語を扱うあらゆるタスクで極めて高い汎用性を示しました。
このTransformerがそれ以前の技術であるディープラーニングより優れている点は下記の3点です。
■Transformerが従来のディープラーニングより優れている点
- スケーラビリティ(拡張性)
- 長期的記憶力
- 学習能力と汎用性
これだけを見ると、すべてにおいて優れているような印象を受けますが、記憶保持や学習能力だけを見ればTransformerよりも優れている方式はほかにもありました。しかし、この中で最も重要な要素は、機械学習に求められる機能を実現しつつ、大規模化が容易な「圧倒的なスケーラビリティ」を誇る点にあります。Transformerのアーキテクチャは従来のものに比べて非常にシンプルだったのです。
今ではTransformerを使ったLLMが数多く登場しています。小規模ながらもGPT-4に匹敵する性能を持つ新しいLLMも登場していますが、基本的には「LLMの規模が大きいほど性能が高い」という原則は健在です。さらに、LLMの知能はその規模が一定ラインを超えた瞬間に突然賢くなる(創発的能力)があることが分かっています。つまり、学習モデルの大規模化はAIが人間の知能に近づくために重要な要素の1つということです。
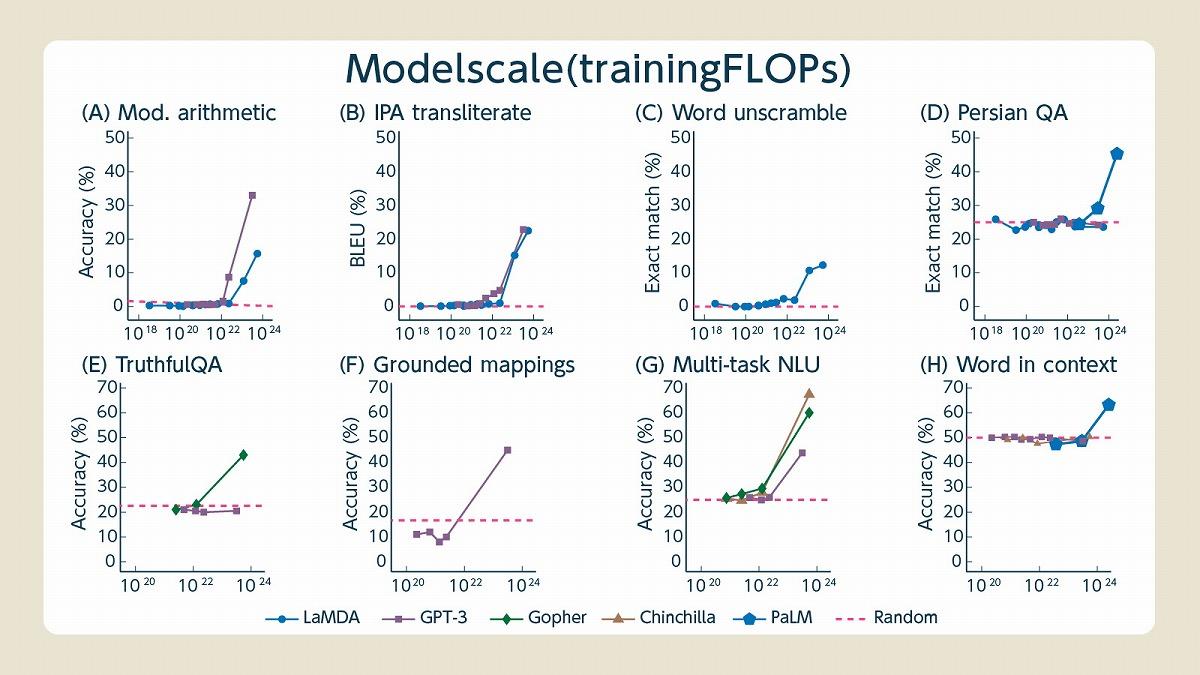
(出典:Emergent Abilities of Large Language Models, Published in Transactions on Machine Learning Research (08/2022), https://arxiv.org/pdf/2206.07682.pdf)
Transformerはこの重要な課題を解決しました。しかし、Transformerの中にはさらに重要な「Attention機構(注意機構)」と呼ばれるアーキテクチャが隠れています。このAttention機構がTransformerの高い性能を引き出しているのです。そこで、次にAttention機構について簡単に説明します。
超重要な関連キーワード、Attention機構とは?
Attention機構というのは、人間の「注意能力」に関する認知機能を模倣したアーキテクチャを持つ機構のことで、目的に応じてさまざまなタイプがあります。どれも似たような機能を持っているものの、その仕組みは少しずつ異なります。Attention機構の基本的な機能は「重要度に合わせた数値計算を行う」という機能で、ニューラルネットワークの重み付けに似ています。ただ、Attention機構では重み付けをより大胆かつシンプルに行っていると考えると良いでしょう。
たとえば、Attention機構を用いて言語処理を行う場合は「単語同士の距離」を見つつ、ある単語にとって「どこの単語が重要か」という考え方で重み付けをしています。単語によって近い単語が重要であったり、遠い単語が重要であったりしますが、距離によって重要性を判別している点は変わりません。極めて単純な関係性の考え方です。
普通に考えれば距離よりも意味のほうが重要に思われがちですが、人間の認知機能でも空間的な距離の関係性は極めて重要な情報に位置付けられており、人間も多かれ少なかれ情報同士の距離で大雑把な関係性を把握していることが分かっています。同じ意味の言葉であっても「倒置法」で言葉のニュアンスが変わることがありますが、言葉の意味ではなく距離や位置を見ることでこうしたニュアンスの違いも把握できるようになります。
このように関係性の把握をシンプルな「距離」によって把握するようになったことで計算コストが軽減されるほか、逆に従来の手法では落としがちだった「遠い情報」を把握しやすくなりました。距離だけで関係性を把握するので、長い文章の最初から最後までの関係性を理解できるということです。これが長期的な記憶力として機能します。文頭の情報が文末まで保持されて、ある程度の長い文章でも綺麗に関係性を理解できるのです。
それだけで言語処理ができる? Attention機構の実力
このAttention機構はシンプルな仕組みだったため、どちらかと言えば発見当初は補助的な技術としてCNNやRNNに導入され、性能を向上させる手法として注目されていました。しかし、TransformerではAttentionを補助ではなくメインに据えて言語処理を行ったことで世界を驚かせたのです。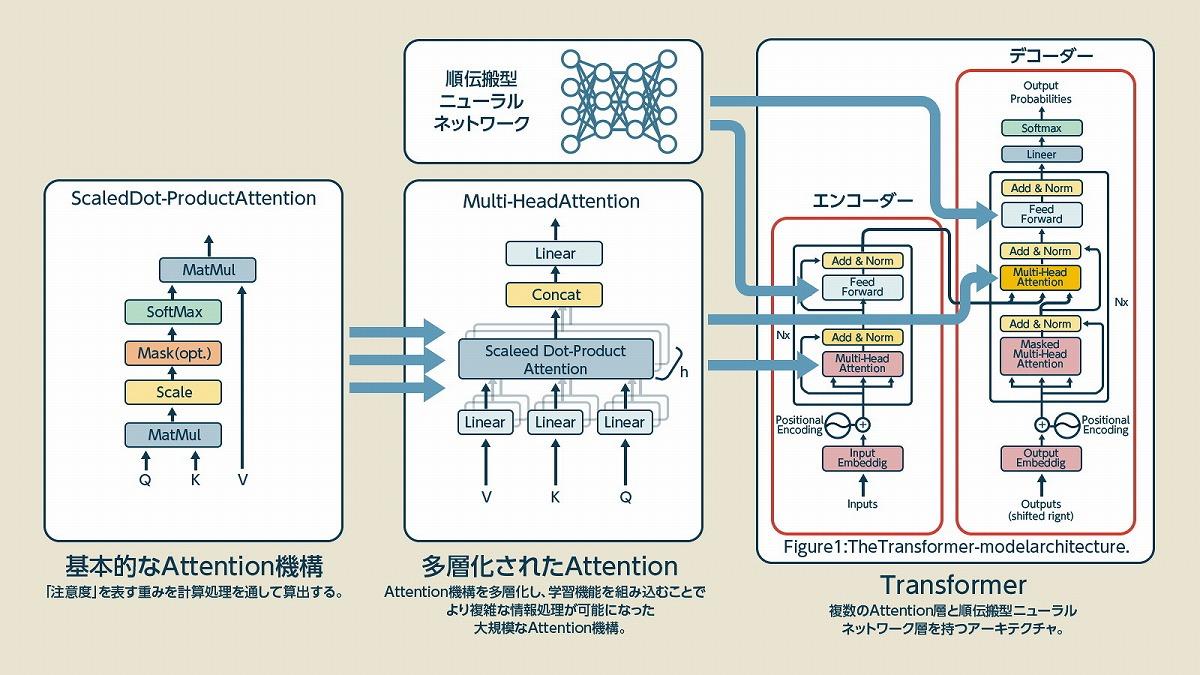
(出典:Attention Is All You Need, https://arxiv.org/pdf/1706.03762.pdf)
上の図はTransformerのアーキテクチャを示す図です。左の「Scaled Dot-Product Attention」が多層化されて「Multi-Head Attention」というモジュールになり、それがTransformerのエンコーダー部分とデコーダー部分に組み込まれています。また、中には順伝搬型のニューラルネットワークも入っています。ちなみに、エンコーダーは機械が理解しやすい形にデータを変換する装置で、デコーダーは人間向けに変換する装置とざっくり考えると良いでしょう。
見る人が見れば「え、それだけ」となるようなシンプルなアーキテクチャで、大規模化することも難しくありませんでした。さらに、近年のLLMでは左半分のエンコーダー部分を切り離して「デコーダー」部分を大量に重ねて動かしています。シンプルで単純なアーキテクチャだからこそ、大規模化も容易になるというわけです。
発展型(1):映像処理向けのVision Transformer
そして、シンプルなアーキテクチャであれば、それを発展させるのも難しくありません。映像向けに開発された「Vision Transformer(ViT)」では画像を細かく切り分けてTransformerの「エンコーダー」に入れる手法がとられました。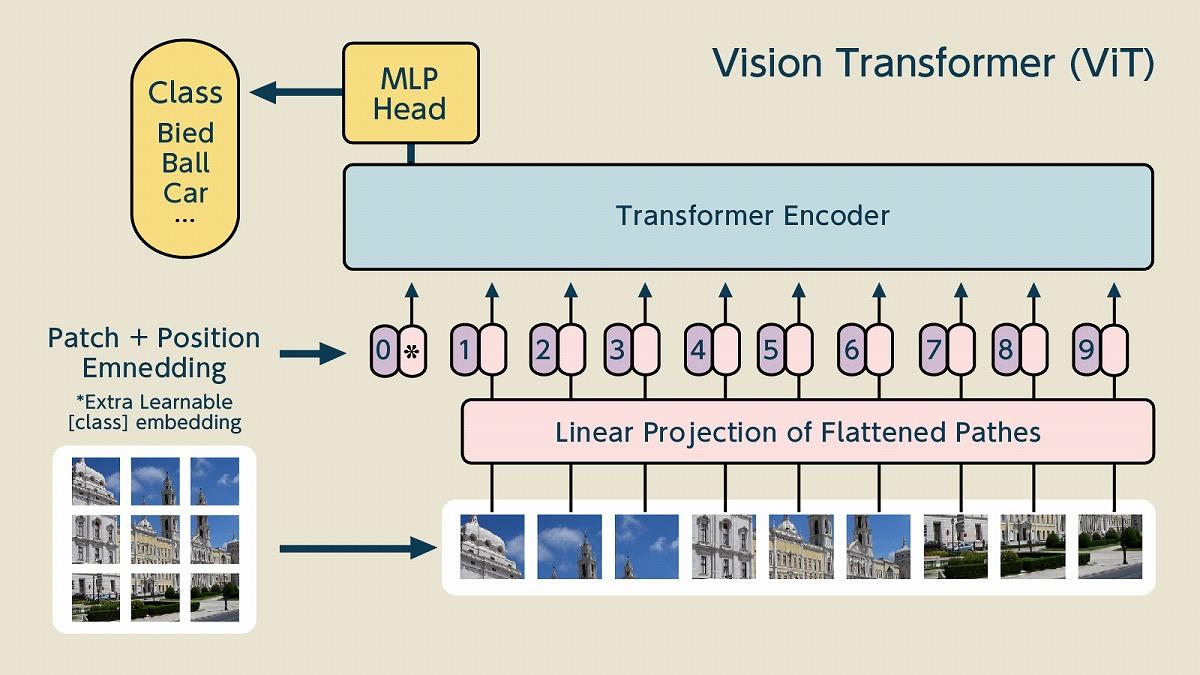
(出典:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE, Published as a conference paper at ICLR 2021, https://arxiv.org/pdf/2010.11929.pdf)
映像においても、切り取った映像間の距離に関する情報を付与して関係性の分析をさせています。映像分析においても距離・位置の情報は、情報の判別・分類をする上で極めて重要なのです。ViTは従来のCNN型の画像分析手法よりも少ない学習データで高い性能を発揮しました。
また、エンコーダーを利用しているのでデコーダーのみで構成されるLLMとの相性も良く、映像と言語のマルチモーダルAIを構築する際にもスムーズにアーキテクチャを構築できる点も強みです。後述のロボット版でも、ViTに近い方式が使われています。 【次ページ】発展型(2):マルチモーダル対応のUnified Transformer
AI・生成AIのおすすめコンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
AI・生成AIの関連コンテンツ
あなたの投稿
PR
PR
PR
