- 会員限定
- 2021/01/18 掲載
強化学習とは何か?「動物そっくり」の機械学習モデルはどんな課題解決に役立つのか
連載:図でわかる3分間AIキソ講座
人工知能(AI)技術の1つである機械学習の中には、教師あり学習や教師なし学習のほかに、「強化学習」のように「行動から学ぶ」タイプの学習も存在します。この手法は人間や動物の学習方法と似ており、実社会では非常に有用な学習方法になると考えられています。そこで、似たような仕組みを持つ「遺伝的アルゴリズム」と合わせて「強化学習」について解説します。
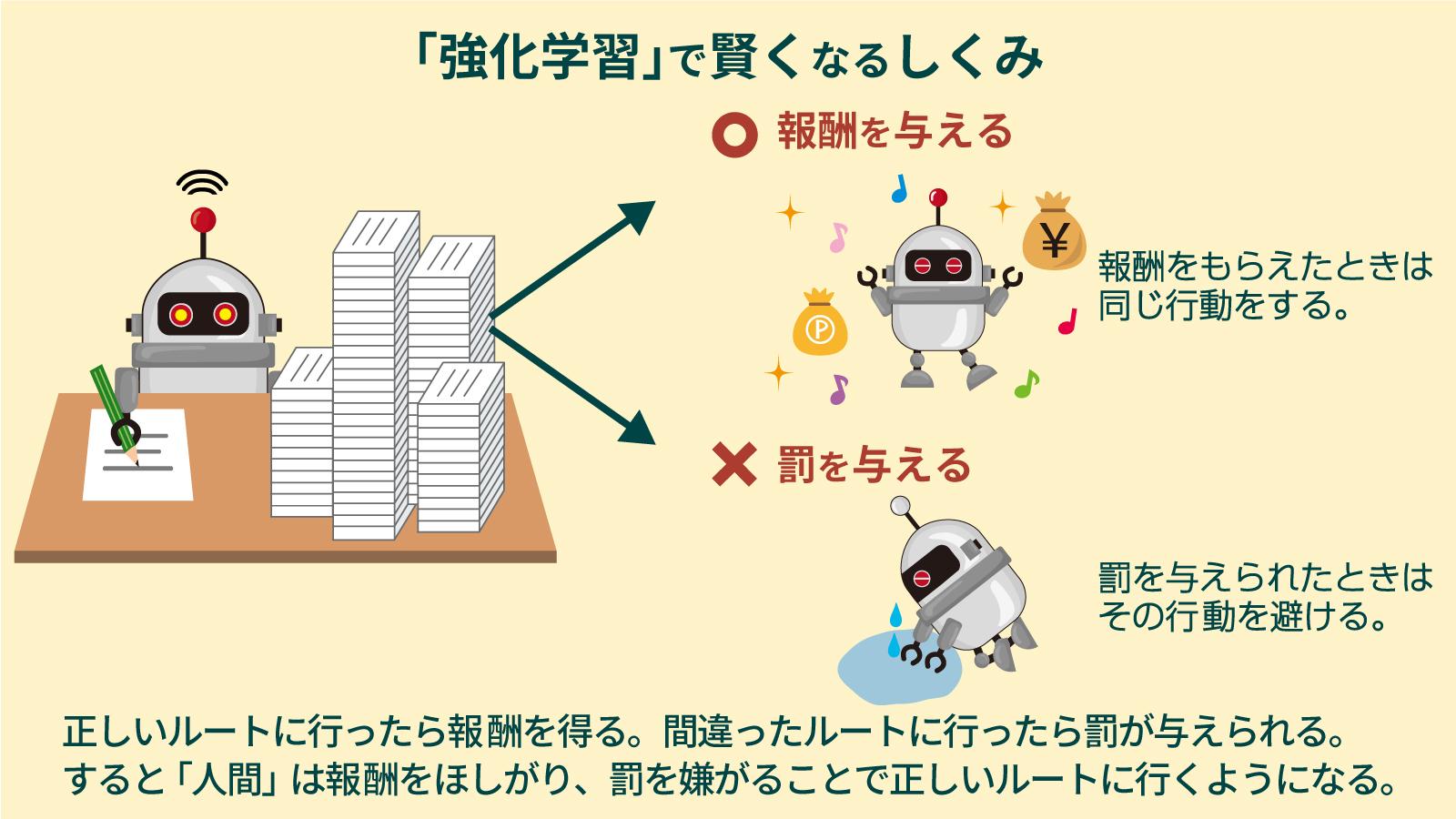
「強化学習」とは
強化学習とは、与えられたデータから学習していくのではなく、自ら行動を起こしその経験から行動を改善していくといった学習方法です。この時、AIには「今回の行動が良かった」や「今回の行動は悪かった」と自らの行動を振り返ってもらうのですが、AIには自らの行動の良し悪しを判断する基準がありません。そこで、行動に報酬を与えることで、その行動が良かったかどうかを理解してらう方法をとります。こうした強化学習の仕組みは「動物にエサを与えて良し悪しを教える調教手法」に似た方法と説明されることが多いです。AIの場合、報酬はエサではなく点数で、目標達成に近づけば加点され、遠ざかれば減点される方式です。スコアが上がるように試行錯誤を重ね、改善を繰り返し、最終的に高いスコアが取れるようにAIの行動が最適化されます。
テレビゲームのスコアをイメージすると分かりやすいでしょう。強化学習の研究では、実際にテレビゲームをやらせて性能テストをするケースが非常に多く、ルールを知らない状態から何万回とプレイを重ね、人間よりも上手にプレイできるようになることも少なくありません。
この学習方法のポイントは、報酬と評価基準の設定次第で多彩な状況に対応できる点にあります。ゲームの場合なら、スコアの設定を「敵を倒す」「目的地に着く」「ダメージを受けない」などの項目のうち、どの項目のスコアを高く設定するかでAIの行動の方針が変わります。攻撃的なプレイか、スピード重視か、安全にクリアするか、すべては報酬(スコア)の設定次第というわけです。
強化学習は、どんな課題解決に役立つか
強化学習は、行動によって生じた結果に対してスコアを設定する方法をとるため、目的がハッキリしておらず、「どんな結果が望ましいか」が分かっていない状況には使えません。その一方で、目的がハッキリしていて「こういう結果が欲しい」と分かっているにも関わらず、そのために「どういう行動をすれば良いか」が分かっていないケースでは有効です。「目的は分かっているが、方法が分からない」というのは、人間社会において非常に多く見られる状況です。「目的地に到着したい」「買い物をしたい」「商品を売りたい」など、目的はあるけど正解が分からないというケースは多々あります。そういう時に私たち人間の場合は、過去の経験に基づいて正解を探し、経験がなければ試行錯誤をながら最適な行動を模索します。
AIの強化学習も同じです。過去の成功体験(スコアの上がった行動)があれば、似たような行動を取りますし、なければ別の行動を取ります。人間と違って、AIにはどうして成功したのか失敗したのかといった「良し悪しの理由付け」ができないので、同じような失敗を繰り返しますが、そこは試行回数でカバーするのがAIと人間の大きな違いでしょうか。
「遺伝的アルゴリズム」とは
試行錯誤を経て学習する強化学習型のアルゴリズムの1つに「遺伝的アルゴリズム」があります。これは生物の「自然淘汰」の仕組みに似ており、失敗したパラメータを廃棄し、成功したパラメータだけを生き残らせていく同アルゴリズムの特徴が「遺伝的」とされる所以(ゆえん)です。
これは原理としては強化学習とあまり変わりません。スコアの高いアクションを成功体験として記憶し、それに似たような行動をとる方式です。ただ、遺伝的アルゴリズムには「突然変異」の要素が組み込まれているのが大きな特徴です。
人間で言えば、ある種の「気まぐれ」のようなものでしょう。本来であればスコアが上がるような行動を取る部分で、スコアが下がるかもしれない行動を取るのです。通常はスコアが下がるのですが、たまにそれがハマってスコアが大きく上がることがあります。
【次ページ】強化学習の落とし穴、なぜ「遺伝的アルゴリズム」が必要か
関連コンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
関連コンテンツ
あなたの投稿
PR
PR
PR
