- 会員限定
- 2017/06/30 掲載
機械学習を「プロジェクトとして成功させる」方法、スキル獲得&人材育成のコツとは
ガートナーのバイスプレジデントが解説
「機械学習=マシンラーニング」は、今もっともホットなキーワードの1つだ。データアナリティクスの需要が爆発的に増える一方で、データサイエンティストの育成・採用はなかなか追いつかない。機械学習はそれを解決する有効な手段として注目を集めているが、実際のビジネスの現場でどう取り組み、そこから有益な知識や指針を引き出していくべきなのか。ガートナー リサーチ部門 バイス プレジデント アレクサンダー・リンデン氏が解説する。

(© taa22 – Fotolia)
※本記事は、「ガートナー データ&アナリティクス サミット2017」の講演内容をもとに再構成したものです。
機械学習の基本的原則となる「算術平均」や「線形回帰」
関連記事
機械学習は、非常に多くのアプリケーションに支えられている。そこには、単純な音声認識だけでなく、画像認識やロボティクスまで幅広い分野が含まれている。そうした複数のアプリケーションを利用して機械学習を成立させる上では、守るべき基本的原則がある。
まずリンデン氏は、その原則を用いた身近な例として、ナレッジをデータから抽出するという試みの中でも、私たちがよく知っている「平均」を挙げる。データの合計をデータ数で割る、いわゆる「算術平均」だが、実はこれも機械学習のモデルの一つなのだという。
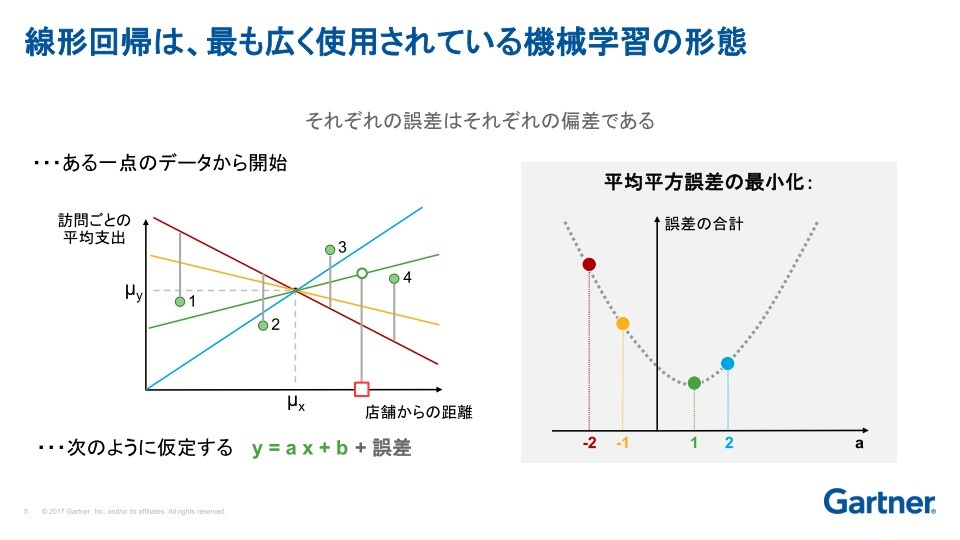
「次のステップとしてあるのが『線形回帰』だ。線形回帰はもっとも広く使用されている機械学習のモデルの一つで、複数のデータの間にある相関関係を、直線モデルによって表し、理解しようとする分析手法だと知って欲しい」
たとえば、もし自分が小売業者だとして、それぞれのお客さまから店舗までの距離は知っているが、一人ひとりのお客さまが、どれくらいお金を使ってくれているのかはわからない。しかし、店舗からの距離に沿って、お客さまの来店ごとの平均支出額はわかるという場合、これを線形回帰のモデルに当てはめてみるとどんなことが見えてくるだろうか。
x軸をお客さまから店舗への距離、y軸を訪問ごとの平均支出額として、4人のお客さまのデータ分布に対して、ある一点のデータを基準にして直線を引き、実際のお客さまデータにもっとも近いのはどれかというのを見ていく。このラインが実際のデータから遠いほど誤差があるということになる。
「グラフでは、緑色の線が4人のデータにもっとも近い。すなわち、いちばん誤差が少ないということがわかる。この線形回帰のような、言い換えれば正当化という考え方が機械学習の基本となる」と、リンデン氏は説明する。
(出典:ガートナー)
発展途上だが大きな可能性を秘めているディープラーニング
続いてリンデン氏は、「ディープラーニング」について触れ、この技術がもっとも得意とする分野のひとつに画像認識があると指摘する。その仕組みを非常に単純化して説明すると、入力された顔写真のピクセルデータに対し、基本的な形状の分析から始めて、だんだんと複雑な形状へと進み、その一連の学習行動を無数に反復することで、精度を高めていくという流れになる。
また、この一連の処理では、画像データを高速で反復解析するため、非常に高性能のGPUのアーキテクチャを備えたシステムが要求されるという。
すべてを解決してくれるように思えるディープラーニングだが、もちろん長所と短所がある。もっとも得意とするのはシーケンシャルな問題処理で、機械翻訳のプロジェクトなどできわめて有効だ。リンデン氏は「ここには音声認識やテキスト認識など、大変有用な技術が盛り込まれ、非常に興味深いことが日々起こりつつある」と期待を隠さない。
「とはいえ、ディープラーニングのアルゴリズムは、万能ではない。期待通りの素晴らしい解を出してくれるかは確約できないし、数学的な定義もない。試行錯誤するしかないのである。解を得られたとしても、それがどのように動作するかは不透明だ」
取り組みを始める前に認識・解決すべきさまざまな課題
では、ここまで見てきたような機械学習の重要課題を、どう解決していけばよいのだろうか。リンデン氏は、機械学習への取り組みがなかなか進まない原因を「いちばんの問題は、機械学習を利用する人々自身がどのようにデータを活用し、生産性を挙げていくのかが、いまだに取り組みの途上にあるということだ」と説明する。このためプロジェクトに拡張性がなく、非常にコストがかかり過ぎる嫌いがある。またほとんどのプロジェクトは孤立したまま進められ、アジリティとコラボレーションが不十分だという。
また機械学習に用いるデータにも、大きな課題が残っている。必要とするデータは手に入れたものの、果たしてこのデータが現実を正確に反映しているかはわからないのだ。
「たとえばアンケートの結果があったとしても、アンケートに答えたくない人はそもそも参加しない。つまり目の前にあるアンケート結果は、ある程度アンケートに参加する意思があった人だけのデータなのだ。すべてのデータには、こうしたバイアス=偏りがある。それを忘れると、現実とは隔たった成果を手にしてしまうことになる」。
また機械学習は一度行ったらそれで完了ではない。たとえば市場での顧客のふるまいは常に変わる。新しい商品が発売される。あるいは新しい競合他社が現れれば、当然顧客のふるまいはその影響を受ける。そうなれば、今まで使ってきたモデルは当然無効になり、もう一度機会学習を実施しなくてはならない。
この「モデル管理」または「パフォーマンスマネジメント」と呼ばれている部分が不十分だということが往々にあって、機械学習の落とし穴の一つになっている。もちろん、モデルが作り直しになるたびにたびたび発生するコストも、機械学習を導入する上での悩みの一つだ。
リンデン氏は、もう1つの落とし穴であり、非常に複雑な問題として、何が機械学習でできて、何ができないかという境界が非常に曖昧で理解しにくい点に言及する。
「それらを明確に線引きできる、明確なフレームワークのようなものは存在しない。多くの場合、機械学習のプロジェクトがうまくいかない理由は、ここに起因するケースが少なくない」
【次ページ】データサイエンスのライフサイクルをどう回していくか
関連コンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
関連コンテンツ
あなたの投稿
PR
PR
PR
