- 会員限定
- 2018/11/15 掲載
機械翻訳の仕組みを図解、直訳タイプと意訳タイプの違いは?
三津村直貴の“今さら聞けない”テクノロジー講座
インターネット上で言語データを自由に集められるようになったことで、従来の機械学習とは全く違った統計学的なアプローチが可能になり、機械翻訳は急速に進歩しました。機械翻訳によって、外国語の学習はおろか翻訳家や通訳が不要になるとさえ言われてるようになっています。それは本当なのでしょうか。機械翻訳の仕組みを解説していきます。
機械翻訳の仕組みは大きく分けて2つ
機械翻訳には、大きく分けて2つの方式があります。1つはルールベース型の翻訳で、もう1つが機械学習を用いた統計ベース型の翻訳です。どちらか一方だけが使われるというわけではなく、最近の機械翻訳では多かれ少なかれ双方の要素が取り入れられています。これらの方式には共通する部分もあれば、全く異なる部分もあるため、機械翻訳を理解するにはこの2つの方式を正しく理解しておくことが重要になるでしょう。
●ルールベース型
まず、感覚的に理解しやすいのはルールベース型の翻訳です。一般的にイメージされる「機械翻訳」はこちらでしょう。
文法と辞書を照らし合わせながら訳文作るようなもので、機械翻訳では文法を「アルゴリズム」によって機械に教え、辞書には「コーパス」と呼ばれる言語データベースを用います。同じ単語でも文法上のどの用法で使われているかによって意味は大きく変わるため、それを踏まえたコーパスづくりが非常に重要です。アルゴリズムによって文章の単語を文法に沿って切り分け、コーパスを直接参照しながら翻訳しています。
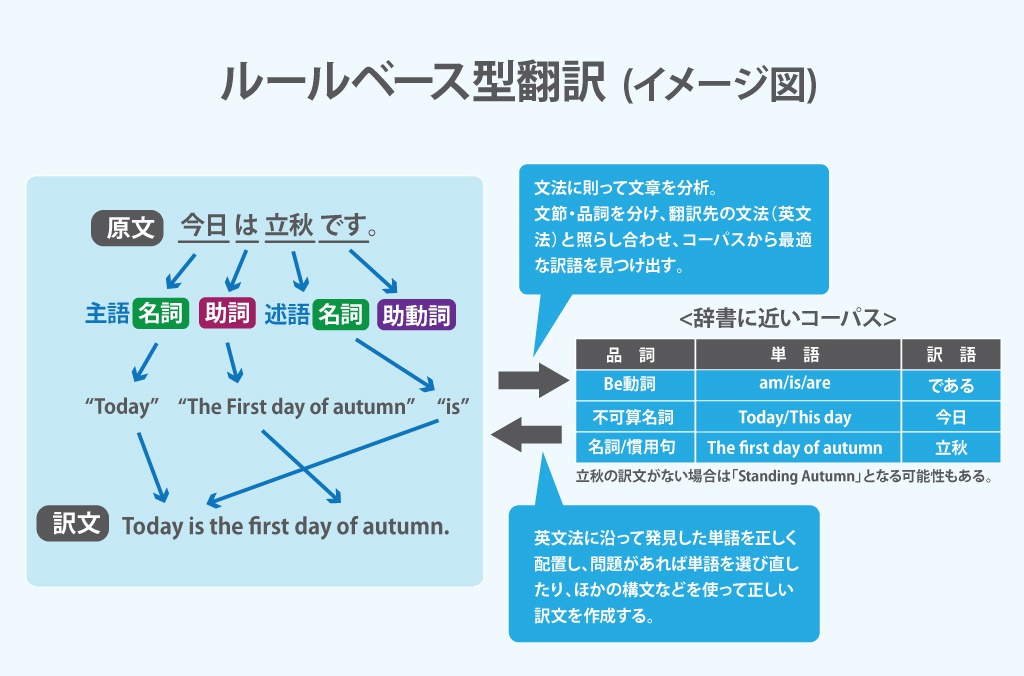
文法を機械的に解釈して単語を切り分け、辞書から訳語を引き出し、訳語を文法に沿って並べています。仕組みとしても分かりやすく、人間の言葉がきちんと文法に則って用いられていれば、極めて有用な機械翻訳の手法です。ただ、実際には文法通りに書かれる言葉は少なく、口語的な文にはほとんど対応できないという課題もあります。
また、機械翻訳で使うコーパスは人間が使う辞書とは違って言語をかなり構造的に分析しデータベース化しています。人間の辞書をそのまま使うわけにはいかず、統計的アプローチが登場する前はかなりの手間をかけて人力で作られていました。
ルールベース型では機械翻訳を行うためのアルゴリズムづくりも非常に重要ですが、コーパスの構築も大切です。英語圏では早期にさまざまなコーパスが構築され、機械翻訳に活用されていましたが日本語ではコーパスの生成も遅れていたため、機械翻訳の精度はなかなか上がりませんでした。
●統計ベース(機械学習)型
統計ベース型はインターネットの登場とコンピュータの進歩により発達してきた方式です。インターネットを通じて非常に簡単にデータが集まるようになり、特に翻訳の場合は原文と訳文を同時に手に入れることも容易になりました。
そこで原文と訳文を使って「対訳コーパス(パラレルコーパス)」と呼ばれるコーパスを活用します。従来のコーパスはあくまで辞書をデータベース化したようなもので、単語レベルで意味を扱ってきましたが、対訳コーパスは従来のコーパスとは違って「文章」や「段落」レベルで原文と訳文のデータベースを作っています。
文章はわずかな違いで意味が変わるため、原文が少し違うだけで訳文も変わります。統計ベース型ではこれをそのまま辞書にするのです。つまり、人間が文脈やニュアンスを踏まえて訳した文章を使ってデータベースを作り、それを元に機械翻訳を行います。
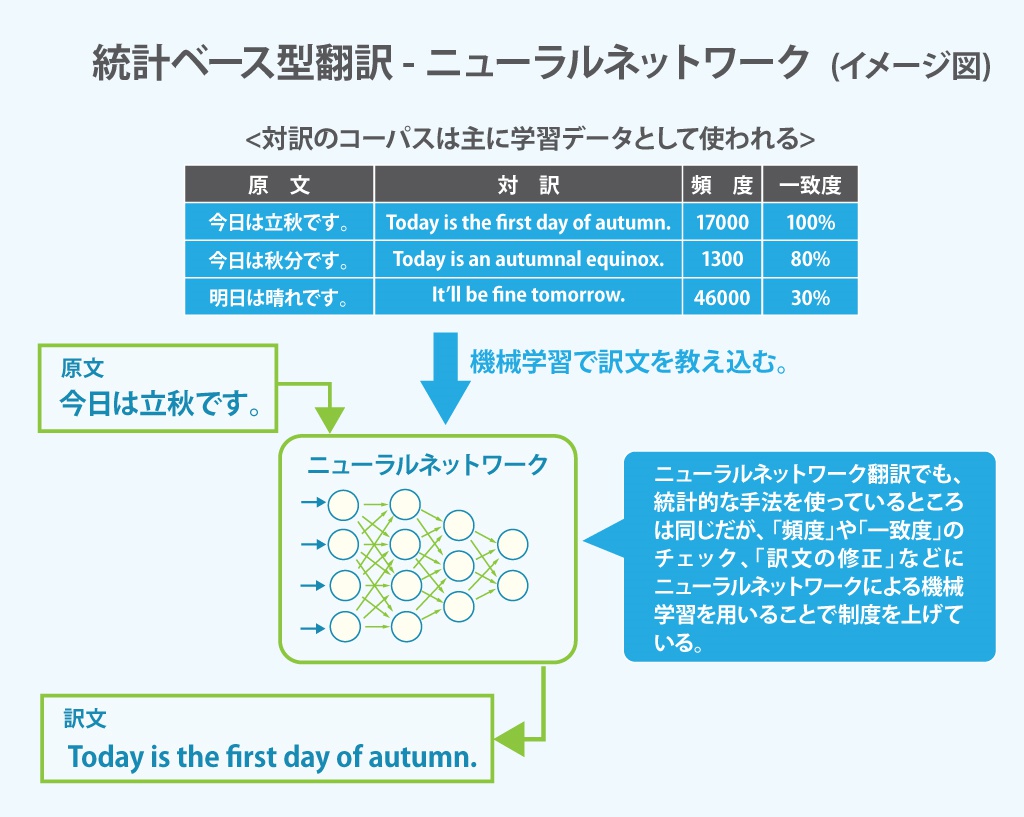
しかし、対訳コーパスだけでは翻訳はできません。機械学習によって「似たような意味の文章」や「似たようなフレーズ」を対応させる訓練を行うのです。表現の方法が微妙に違っていても同じような文章として訳文を作れるように学習を重ねることで、初めて見た文章からも「似たような意味の訳文」を作れるようになるのです。
統計ベース型では、この対訳コーパスと機械学習が性能のキモになります。データが無ければ学習はできず、データがあっても学習ができなければ翻訳はできません。近年、対訳コーパスはビッグデータの登場により充実し、機械学習については大規模ニューラルネットワークの学習法である「ディープラーニング」の登場に飛躍的に進歩しました。あまりに急激に進歩したため、ニューラルネットワーク型の機械翻訳を従来の統計ベース型の機械翻訳と区別するケースも増えています。
また、最近ではルールベース型にも訳語の選択に対訳コーパスを使った統計的なアプローチが組み込まれるようになっており、「ルール+統計型」と「ニューラルネットワーク型」で分けて考えられるケースも少なくありません。
直訳タイプのルールベースと意訳タイプの統計ベース
上記のような翻訳のタイプによって、ルールベース型は「直訳タイプ」、統計ベース型は「意訳タイプ」と分けることができます。以下が、それぞれの強みと弱みです。| 方式 | 強み | 弱み |
| ルールベース型 →直訳タイプ |
●データの少ない言語間の翻訳にも強い。あまり使われない単語なども正確に訳せる。文語に強い。 ●データがなくても独自の機械翻訳システムが作れる。 ●専門家がコーパス作りに参加することで専門書向きの翻訳システムが作れる。 |
●意味は通るものの、かなり不自然な訳になる。慣用的な用法などに弱く、全く別の意味になることもある。口語に弱い。 ●性能の維持向上に高度な技術をもった言語学の専門家が必要で維持コストがかかる。 |
| 統計ベース型 →意訳タイプ |
●データが充実している場合は人間並に自然な訳ができる。 ●慣用句や文章のニュアンスを踏まえた訳を作れることもある。 ●口語・文語を問わず訳せる。 ●機械学習のインフラを整えれば性能の維持・向上コストは低い。 |
●データの少ない言語間の翻訳に弱い。 ●珍しい用法や語句に弱く、別の意味になることも。 ●一部の単語を無視して訳を作ることがあり、意味は通るが正確ではない訳になることが多い。 ●機械学習用インフラの構築にコストがかかる。 |
ルールベース型の直訳タイプの翻訳は文法と単語の意味に忠実であり、正しいアルゴリズムとコーパスが作られていれば、あまり使われないフレーズや文章でもそれなりの精度で訳せます。ただ、極めて機械的な翻訳であり、訳文は人間のようなクオリティにはなりません。
関連記事
それでも、専門領域に特化したコーパスを作ることで、専門分野に特化した機械翻訳システムを構築することが可能です。専門分野では、同じ単語でも一般的に使われない訳語が用いられることが多いため、統計ベースの翻訳では上手く訳せないことが多いのですが、特化型の機械翻訳であれば及第点の訳が出てきます。全体的に直訳的な翻訳ではありますが、分野別に用いることで優良点ではないものの赤点でもない無難な翻訳が出来上がります。
一方、統計的アプローチは十分な学習データと優れた機械学習法を用いれば人間のような自然な翻訳を作ることが可能です。データ量が多ければニュアンスを踏まえた翻訳や慣用句などにも対応できます。
ただ、どうしてもデータ量によって訳し方に傾向が生まれるため、珍しい訳語が登場する専門分野や皮肉を踏まえたジョークなどが含まれるとうまく訳せないことも多いです。
また、自然な訳にするために単語を無視することもあり、「ジャンルが似ているから」という理由で明らかに違う意味の訳を当てることもあります。なまじ自然な訳になるため、信頼しすぎて誤訳に気づかない可能性もあるでしょう。大半の文章で自然な翻訳ができる反面、苦手分野で凡ミスをすることもあると考えるとわかりやすいでしょう。
ニューラルネットワークを利用した新しい統計的機械翻訳が登場し、機械翻訳は急速に進歩し始めました。大切なのは、それがどの程度のレベルに達しているかということです。ビジネスに使えるレベルという話もあればまだまだそのレベルには達していないという声もあり、現状を正しく理解することが大切です。次ページからは「Google翻訳」などを例に、機械翻訳の特性と限界について説明します。
【次ページ】統計翻訳がなぜ万能ではないのか
関連コンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
関連コンテンツ
あなたの投稿
PR
PR
PR
