- 会員限定
- 2017/06/09 掲載
SparkとHadoopは何が違う? 混沌とするOSSを生かしたデータ分析基盤構築の勘所
ビッグデータ活用の機運が高まる中、SparkやHadoopを導入して、データアナリティクス利用基盤の構築に取り組む企業が増えている。市場もソフトウェア環境も激しい成長と変化を続ける中、これらのデータ分析プラットフォームは現在どのように利用されており、そして新たなユースケースやシナリオの実現に向けて、今後どのように進化してゆくのか。ガートナー リサーチ バイス プレジデント マーヴ・エイドリアン氏が解説する。

(© vladimircaribb – Fotolia)
※本記事は「ガートナー データ&アナリティクス サミット 2017」の講演内容をもとに再構成したものです。
根本的に異なるアーキテクチャを持つHadoopとSpark
関連記事
オープンソースソフトウェア(OSS)のエンタープライズ領域における活用が急速に拡がる中で、顧客から寄せられる質問も変わってきている。その一つが、OSSに関わるリスクだ。一口にOSSの導入・利用といっても、現状は決して容易ではない。しばしば自社の中にないスキルが求められ、そのスキル自体も急速に変化し続けている。
ガートナー リサーチ部門のバイス プレジデント マーヴ・エイドリアン氏は「それにもかかわらず、OSSへの関心は高まる一方であり、企業のシステムの中に占めるウェイトも、好むと好まざるにかかわらず確実に増えつつある」と指摘する。そうした中で、もっともよく大きな関心を集め、利用されているのが、ビッグデータ分析基盤として知られるHadoopとSparkだ。
以下の図を見てもわかるように、両社の機能にはオーバーラップする部分がある。そのユースケースは、似ているところもあれば異なるところもある。だが、根本的な違いは、Hadoopはディスクベースのアーキテクチャであり、Sparkはメモリベースのアーキテクチャだという点にある。異なるアーキテクチャを持っている結果、それぞれに異なった使われ方やシナリオが存在することを、ユーザーや導入を考えている企業はまず念頭に置いておくべきだ。
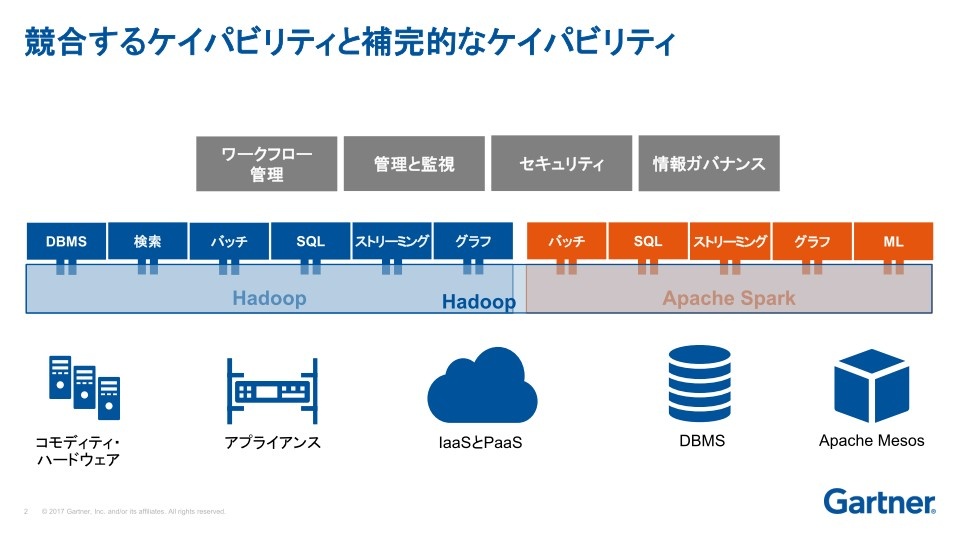
(出典:ガートナー)
HadoopやSparkのOSSベンダーの選定方法とは?
一方、HadoopやSparkを販売しているベンダーも、新しい課題に直面している。このいずれもOSSのスタックであるということは、ユーザーにコンポーネントを売ったりサポートを提供する場合、競合他社とまったく同じものを提供せざるを得ないということでもある。これは他のIBMやマイクロソフト、SAPなどのプロプライエタリなソフトウェアと大きく違う点だ。このためディストリビューターは、自分たちの提供するディストリビューションに細かな機能の変更や追加を行うことで差別化を図っているが、この微妙な違いは同時にユーザーにとっての混乱の原因ともなっている。
「こうした “わかりにくさ” に困惑して、ユーザーは私たちのところに相談にやってくる。OSSの価値を導入したいと考えているが、ディストリビューターごとに小さな機能変更や追加を施されたディストリビューションを採用した結果、ベンダーロックインに陥らないかどうかと懸念している」(エイドリアン氏)
ユーザーにとっての大きな懸念は、もう1つある。クラウドの問題だ。現在Hadoopの顧客の25%はクラウドユーザーであり、それ以外の層にも今後クラウドに移行しようとする動きが活発にみられる。
しかし、どのようにクラウドでデプロイするのか。それによっては、新たなツールの追加が必要になり、その場合、現在のシステムを任されているベンダーは、ツールを提供する競合他社と協力関係を結ばなくてはならないかもしれない。
「こうした状況がいつまで続くのかは誰にもわからず、ベンダーにとってもユーザーにとっても、今後の行方を今なお不透明なものにしている」(エイドリアン氏)
時代を追って大規模データの分析に最適化されたHadoop
Hadoopが用いられた最初のユースケースは、ETLとバッチ処理だった。もともとクリックストリームデータを大量に蓄積していた大手Web企業、たとえばLinkedIn(リンクトイン)やフェイスブック、ヤフーのような会社が、「このクリックストリームから、価値のあるデータを抽出したい」と考えたのである。従来型のリレーショナルデータベースでは扱えなかったこれらのデータを、フィルタリングやソーティングして分析に利用しようともくろんだのだ。「さらに、こうして得られた分析データをデータウェアハウスやデータレイク、さらにオペレーショナル・データ・ストアといった大規模ストレージに展開すれば、将来にわたって継続的に分析に利用するといったことも可能になってくる」(エイドリアン氏)
Hadoopの進化につれ、アーキテクチャの導入モデルも変化してくる。もっとも初期の段階はオンプレミスで、数台のPCの中にデータやソフトウェアがまとめて置かれていた。
その後、クライアントサーバシステムに似た2層アーキテクチャに移行し、アナリティクスへの活用が進むと、DBMSを分離した3層アーキテクチャを実現。さらに現在は、より大規模でのユースケースをまかなうための、論理データウェアハウス・アーキテクチャへと進化を遂げてきている。
【次ページ】SparkやHadoopなどの大容量データ処理技術は今後どう進化していくのか
関連コンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
関連コンテンツ
あなたの投稿
PR
PR
PR
