- 会員限定
- 2021/12/01 掲載
超高精度の言語AI「GPT-3」は何がスゴい?要約、小説、コーディングなど広がる可能性
AIが記事を作り、小説を執筆し、問い合わせにチャットで回答することは当たり前になってきました。その背景にはAIの自然言語処理技術の飛躍的な向上があり、中でも2020年に登場したGPT-3はある種のブレイクスルーとしてAIの界隈以外にも広く知れ渡るようになりました。GPTは従来のAIと比較して、その規模やメカニズムにおいていくつかの注目すべき点があります。本記事では、そんなGPT-3について簡単に解説していきます。

(Photo/Getty Images)
GPT-3とは?文章生成で何ができるのか
GPT-3は「Generative Pre-trained Transformer - 3」の略で、OpenAIが開発した事前学習済み(Pre-trained)の文章生成型(Generative)の「Transformer」、その3番目のモデルを指します。この「Transformer」というのは自然言語処理向けの深層学習モデルのことで、「畳み込みネットワーク」「回帰的ネットワーク」に代表される機械学習モデルの一種ととらえてください。つまり、GPTはTransformerという学習モデルをベースにして、しっかりと事前学習を行い文章生成を行うようにカスタマイズされたAI(言語モデル)ということになります。「文章生成を行うAI」と一言で言っても、非常にさまざまな種類があります。例として「質問や問い合わせに答えるもの」「会話を成立させるもの」「自然な文章を作るもの」などがあり、GPTはその主たる用途を踏まえると「自然な文章を作るもの」にあたります。これだといまいち使い方がパッとしないイメージがありますが、自然な文章を作るスキルを極めるとその他の用途にも幅広く使えるようになります。
たとえば「この記事ではディープラーニングという技術について解説します。まず、ディープラーニングとは――」という文章があった場合、次に来る文章として自然な内容は「ディープラーニングの解説」です。これを使えば「ディープラーニングとはなんですか?」という質問やその他の問い合わせに答えることが可能になります。また、それは会話においても同様です。小説のワンシーンのように「今日はいい天気ですね――」という文章があったなら、次には「ええ、暑いですね」や「そうですね」と言った言葉が来るのが自然です。自然な文章を作る技術を使ってチャットボットが作れるというわけです。
ただ、簡単な会話や質問ならまだしも少し複雑な文章はある程度の知識や常識がなければ作れません。それこそ「ディープラーニング解説をする」といいつつ知識がなく、ごまかすために「長くなるので詳しくはネットで調べてください」と続いたら、不自然とまでは言えないもののやや期待を裏切る流れとなります。
文法的に自然な文章は作れても、知識を上手に使った文章生成は非常に難しい技術ということです。それをGPT-3では、膨大なデータベースとそれを効率的に扱えるTransformerという学習モデルを採用することで、従来より遥かに多彩で複雑な文章を作れるようになりました。
「Transformer」に使われている「Attention」とは?
GPT-3の仕組みを理解するには、まず「Transformer」を理解する必要があります。ところが「Transformer」を理解するには、そのコア技術である「Attention」というニューラルネットワークのアルゴリズムについて理解しなければなりません。そこまで解説すると長くなるのでネットで調べてくださいといいたいところですが、そんな記事ならGPT-3でも書けそう(本当に書きます)なので簡単に「Attention」の仕組みについて説明します。Attentionは「注意」を意味する英語ですが、仕組みもその名の通り「どこに注目するか」に焦点を当てたニューラルネットワークのアルゴリズムになります。Attentionでは、それぞれの「単語」や「文章」のどこが重要で、どの関係性に重きを置くべきなのか「だけ」に着目します。余計な情報をごちゃごちゃと取り込むことはありません。シンプルですがこれは画期的なアプローチです。
言葉というのは順番に読んでいくものなので、従来は回帰型ネットワークのような、情報がネットワーク内を循環していくような複雑なネットワークを使って学習していました。すべての単語や文章が循環することで、単語による意味の変化や文章全体の関係性を正確に捉えることができたのです。しかし、これは膨大なデータ処理に向きません。原理的には優秀なものの、膨大な知識を処理しようとすると負荷が重くなり実用的なレベルに達しませんでした。
これに対してAttentionはシンプルな機構であるため負荷が軽く、なおかつ文章を理解するためのまさに「要点」を抑えているため、膨大なデータセットであっても高い精度で学習ができたのです。Attention自体は従来の畳み込みネットワークや回帰型ネットワークと組み合わせることで注目されるようになったのですが、Transformerでは「Self-Attention」と呼ばれるAttentionの改良型を組み合わせることで従来の畳み込みや回帰型の複雑なネットワークを使うことなく優れた自然言語処理能力を示しました。
実際に「Transformer」を使ったグーグルの言語モデル「BERT」が開発され高い性能を発揮すると、OpenAIはTransformerで「GPT」を作り、さらにGPT2、GPT3と発展させることで自然言語処理の分野に大きなインパクトを与えました。
GPT-3はどのように自然な言語を作っているのか
新しく登場したAttentionやTransformerはGPT-3を構成する重要な要素であり、自然言語処理の分野では画期的なアイデアとして広く普及しました。しかし、実はこれらの技術は「非常に効率的に言語処理ができるようになった」ということを意味しているだけで「AIによる自然言語処理の本質的な仕組み」は従来とそれほど変わっていません。基本原理はニューラルネットワークによる自然言語処理が始まった頃に考えられた「Word to Vector(言葉をベクトル化する)」の発展型です。Word to Vectorというのは、要するに「言葉を全部数値のパラメータに置き換えて考えましょう」ということです。あらゆる言語を数値のパラメータに置き換え、そのパラメータ同士の統計的な関係性の問題に置き換えてニューラルネットワークで処理すれば、どんなに複雑な文章であっても処理ができます。GPT-3では、それをTransformerによって極めて効率的に行い、かつ従来の学習モデルの水準を遥かに超える膨大なパラメータを使うことで実用的な水準にまでおしあげました。
このような自然言語処理では、基本的にすべての文章はそれぞれの関係性の一部として理解されます。単語や文章の意味、知識の扱い方については考えておらず、単純に「今日はいい天気ですね」と関係性の深い文章を探し、その次に並べるといった仕組みで運用されます。シンプルですが、シンプルであるがゆえに複雑で膨大なデータであっても扱えますし、応用も簡単です。
この方式では、言葉の意味を理解し、知識がある人間なら「不自然」だと感じられるような文章を作ってしまうことがある一方で、文化的な背景や高度な文脈理解を必要とする「一見すると不自然に見える複雑な文章」であっても十分なデータがあれば作り出すことが可能です。
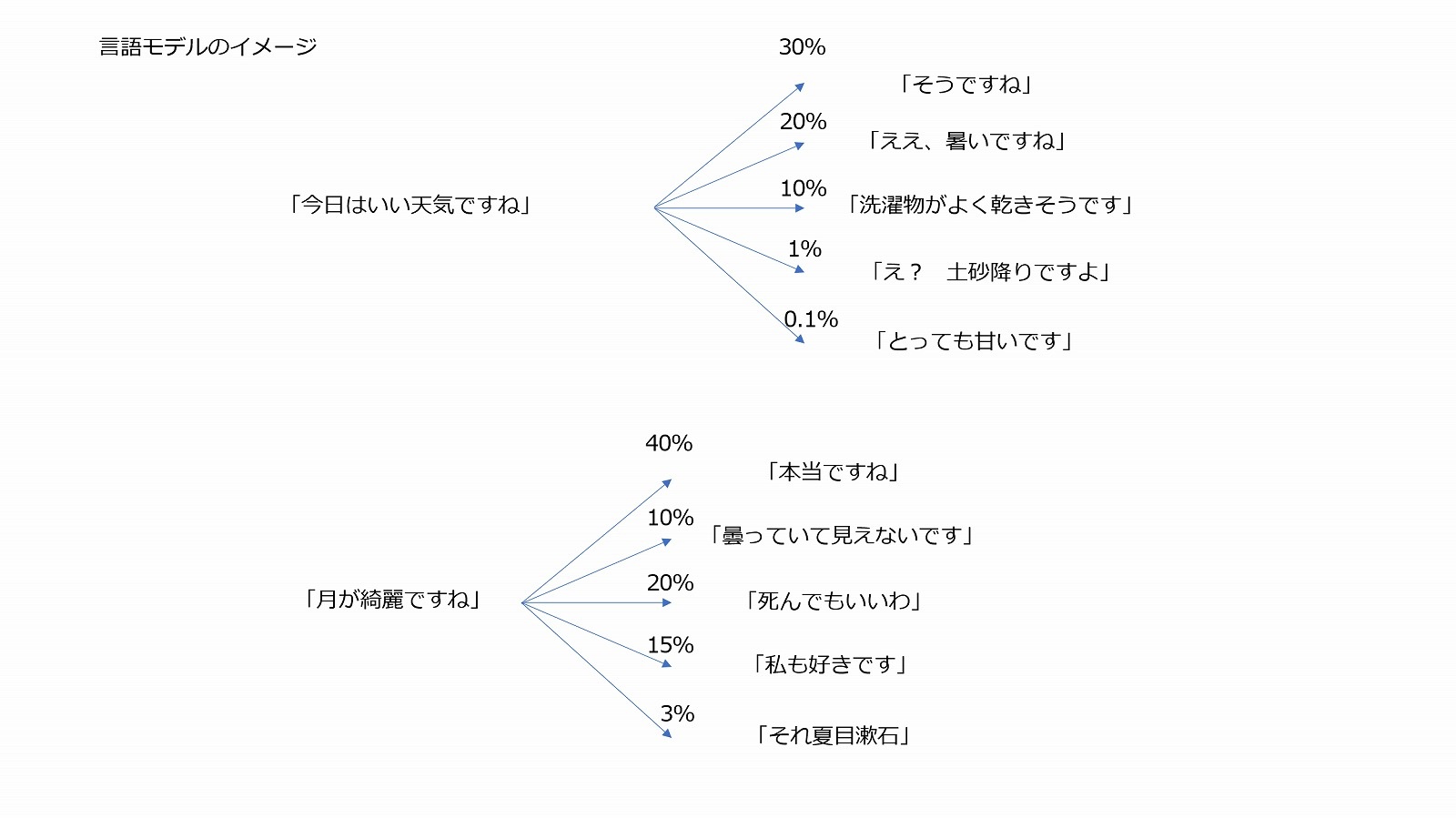
たとえば、夏目漱石が「I love you」を「月が綺麗ですね」と訳した話はよく知られていますが、文章の意味を考えると不自然です。さらに、そこに二葉亭四迷が愛を語る台詞として「Yours.」を「死んでもいいわ」と訳したのを組み合わせ、一見すると不自然でも文学的な愛情表現の一種として広く知られるようになりました。これは日本人が直接的な愛の言葉をあまり言わないという文化的背景と小説内の文脈を踏まえた高度な解釈なのですが、このやり取りは広く知られていることなので自然言語処理で扱うことが可能です。
実際に、Transformerベースの言語処理システムが「月が綺麗ですね」に続く言葉として「死んでもいいわ」と出力しました。文学的表現を理解しているわけではなくとも、十分なデータがあり、関係性が正しく把握されていればこうした文章生成は十分に可能なのです。
【次ページ】GPT-3の応用事例、類似技術「AIのべりすと」の実力と限界
関連タグ
タグをフォローすると最新情報が表示されます
関連コンテンツ
あなたの投稿
PR
PR
PR
