- 会員限定
- 2014/10/16 掲載
590億PVをバリューに変える、ヤフーのビッグデータ基盤構築における2つのポイント
検索やオークション、ショッピングなど、PCとスマートデバイス向けを併せて100種類以上のサービスを提供するヤフー。月間アクティブユーザーID数が約2800万人、月間総ページビュー数が約590億で、年間ユニーク検索クエリ数は実に約75億にのぼる。同社のこうしたビジネス展開を支えているシステム基盤はどのような仕組みになっているのか。NEC主催「ビッグデータ時代のデータ活用とITインフラ」セミナーで登壇したヤフー システム統括本部 データソリューション本部 TD室 室長の日比野哲也氏が、その取り組みについて語った。
レッド オウル
編集&ライティング
1964年兵庫県生まれ。1989年早稲田大学理工学部卒業。89年4月、リクルートに入社。『月刊パッケージソフト』誌の広告制作ディレクター、FAX一斉同報サービス『FNX』の制作ディレクターを経て、94年7月、株式会社タスク・システムプロモーションに入社。広告制作ディレクター、Webコンテンツの企画・編集および原稿執筆などを担当。02年9月、株式会社ナッツコミュニケーションに入社、04年6月に取締役となり、主にWebコンテンツの企画・編集および原稿執筆を担当、企業広報誌や事例パンフレット等の制作ディレクションにも携わる。08年9月、個人事業主として独立(屋号:レッドオウル)、経営&IT分野を中心としたコンテンツの企画・編集・原稿執筆活動を開始し、現在に至る。
ブログ:http://ameblo.jp/westcrown/
Twitter:http://twitter.com/redowlnishiyama
業務改善のPDCAサイクルの各フェーズで、ビッグデータを活用

システム統括本部
データソリューション本部
TD室 室長
日比野 哲也 氏
「サービスを運営する中で我々は利用者のさまざまな行動、たとえばどんなキーワードで検索したのか、ショッピングで何を買ったのか、地図でどこを見たのかといった多種多量のデータを保持している。しかし単にデータがあるだけでは何も生まれない。ここから価値を生み出すには、これらビッグデータを十分に活用する必要がある」
そのためヤフーでは、業務改善におけるPDCAサイクルのあらゆる場面で、ビッグデータを活用している。
たとえばPlanのフェーズでは、“萌芽検知”という取り組みがある。あるキーワードの検索回数の変化を時系列に沿って見るもので、これにより世間で関心が伸びつつある事柄を早期に発見し、そこからユーザーニーズの変化やマーケットの変化をいち早くキャッチして、適切な施策立案につなげていく。
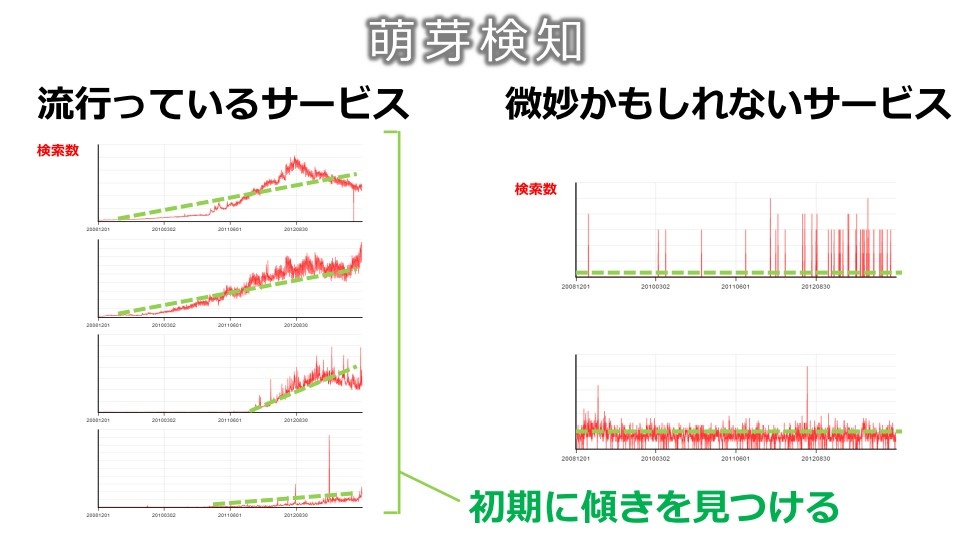
(出典:ヤフー講演資料)
関連記事
次にDoのフェーズでは、ビッグデータを利用してさまざまなサービスを展開している。具体的には、検索窓に入力されたキーワードに関連して、次に打ちこまれるキーワードを予測し、ユーザーに提示する“検索キーワードの入力補助”や、ショッピングやニュースなどで、ユーザーが関心のありそうな商品やニュースを推測して提案する“レコメンデーション”などが挙げられる。
さらにCheckとActionのフェーズでは、ビッグデータを分析することでさまざまな施策の効果を検証し、次のアクションを決める取り組みを行っている。
わかりやすい例がA/Bテストで、サイトのデザインやレイアウトを数パターン出し分け、ユーザーの実際の反応を見ながら最適な形を決めていくというものだ。ヤフーのサイトでは日々、さまざまなテストが行われており、その結果に応じてレイアウトを調整しているという。
「たとえば、スマートフォン版Yahoo! JAPANトップの検索窓の枠線を中太にした場合、細い枠線の時と比べて、検索誘導率が2%向上した。我々は検索連動型広告というサービスも提供しているが、検索誘導率のアップによって、広告の年間売上高は約5億円増えた。まさにビッグデータの活用がビジネスにつながった好例だ」
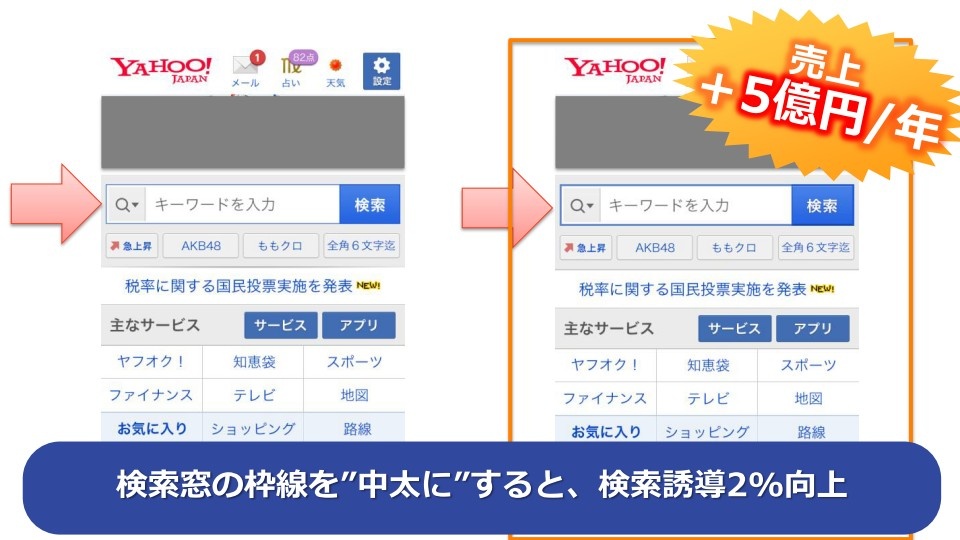
(出典:ヤフー講演資料)
バリューにつながるシステムの1つめのポイントは、“入力基盤の強化”
ビッグデータを活用して数多くのビジネス価値を生み出しているヤフーだが、そのためにはデータ活用を支えるIT基盤が必要不可欠だ。それではどうすれば、バリューにつながるシステムを構築することができるのか。「先に紹介したようなPDCAサイクルにおけるデータ活用例は、1つ1つを見ると小粒なもの。しかしこうした取り組みが、業務の至るところで行われるようにならなければ、会社としての大きな効果には結び付かない。そこで我々はデータ活用のためのシステムを構築するに当たって、特に2つのポイントを意識してきた」
その1つめが、入力基盤を強化することだ。
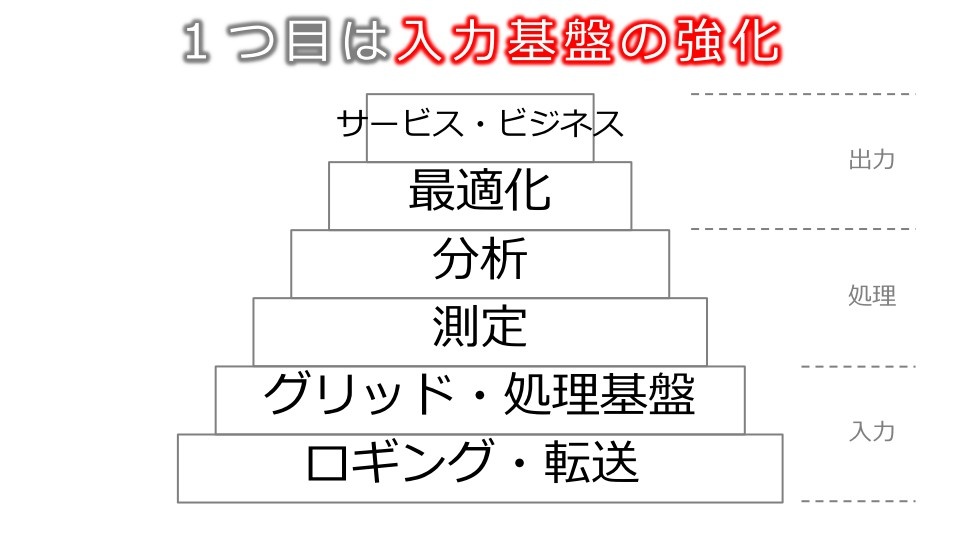
(出典:ヤフー講演資料)
データを活用するためのシステムの構造は入力部、処理部、出力部に分けられる。まず入力部には、データを集めたり、転送したりする機能があり、その上にグリッドコンピューティングやHadoopのようなデータ処理基盤がある。続いてデータを測定/分析するためのシステムがあり、さらにその上に最適化を図ったり、実際のビジネスやサービスで使うためのシステムが存在する。
「こうした構造を考えた時、出力側だけを大きくするのは現実的ではない。少ないデータを使って複雑な分析をしても、良い結果を得られることは稀である。実現可能な施策は、取得できるデータやコンピューティングパワーなどに依存する。必要なデータをしっかりと取得し、適切な処理を行い、測定/分析できる下地があって初めて、具体的なビジネスやサービスにつながるということ。入力基盤が大きくなればなるほど、サービスやビジネスの可能性も広がる」
またヤフーは処理部の機能も非常に重視しており、1ノードで4000台規模のHadoopのクラスタとTeradataのデータウェアハウスを持つ同システムは、共に日本最大級の規模となる。
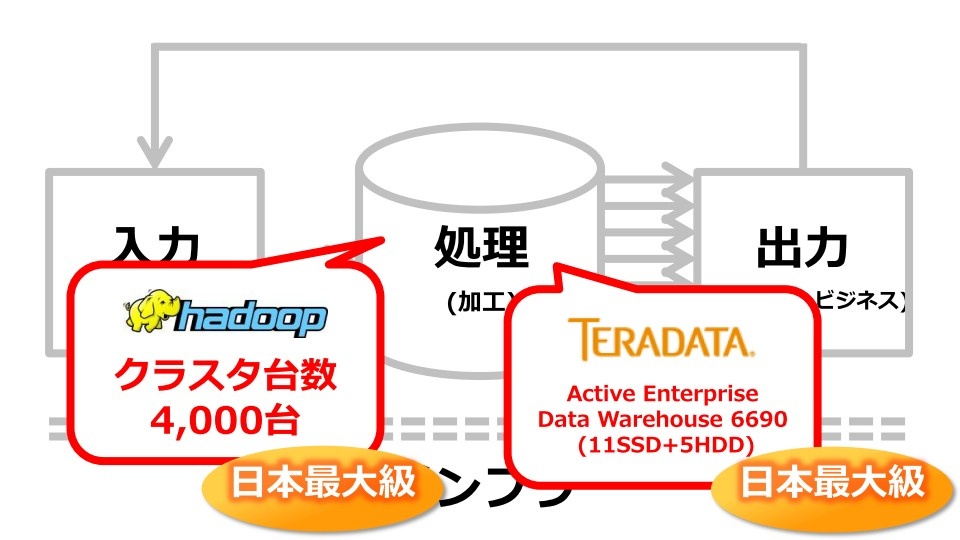
(出典:ヤフー講演資料)
「一般的な企業では、データを分析する、あるいはデータを使ってサービスを運営する部分を重視することが多いが、我々は、ロギングのシステムやデータを回収するためのシステム、またグリッドコンピューティングや音声認識、自然言語処理など、データそのものを理解するためのテクノロジも非常に注力しており、そのための部隊を設置している」
関連記事
【次ページ】“データドリブンな組織”の条件とは?
データ戦略のおすすめコンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
データ戦略の関連コンテンツ
あなたの投稿
PR
PR
PR
