- 会員限定
- 2016/02/23 掲載
データ容量が1年で4倍になるYahooは、増大するデータ需要をどう解決するのか?
Hadoop Spark Conference Japan 2016
日本を代表する規模のビッグデータ処理基盤を持つ企業の1つがYahoo! Japanです。同社は2月8日に開催された「Hadooop Spark Conference Japan 2016」において、現在運用中のビッグデータ処理基盤の規模、そして同社が抱えている課題と、それをどう解決していくのかを基調講演の中で示しました。
関連記事
Yahoo! Japan(以下Yahoo!)が示した解決方法は、Hadoopなどのビッグデータ処理基盤を使い倒す側から、作る側へ向かうという大胆なものです。同社の貢献はオープンソースとなり、今後さらに多くの課題解決に役立つことになりそうです。同社データインフラ本部 遠藤禎士(えんどうただし)氏のセッションをダイジェストでまとめました。
Yahoo!はマルチビッグデータカンパニー
Yahoo! Japan データインフラ本部 遠藤禎士(えんどうただし)氏(写真左)。
現在Yahoo! Japan(以下Yahoo!)は100以上のサービスを提供し、月間649億ページビュー、1秒間に5万アクセスの規模のマルチビッグデータカンパニーです。

ビッグデータ基盤の全体像として、HadoopのうえにRDB、DWH、オブジェクトストア、KVS(キーバリューストア)が乗っている構造になっています。
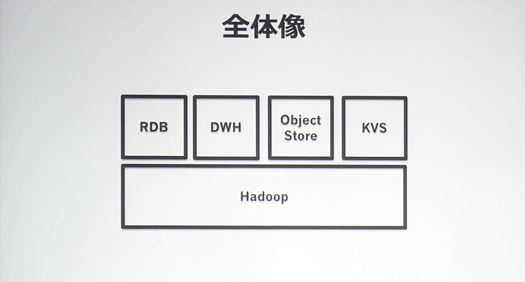
Hadoopクラスタは6000ノード、120ペタバイトのデータを保持。

その上のサブシステムは以下のようになっています。
・RDBはMySQL(Percona)のデータベースが560個、Oracleのデータベースが200個。
・DWHにはTeradetaを利用し、43ノードで1.7ペタバイト、1日平均30万クエリを処理。
・オブジェクトストレージは同社のプロプライエタリなもので、1500ノード以上あり10ペタバイト以上のデータを保持。1カ月あたりのギガバイト単価は2円
・KVSはCassandraで2000ノード、1秒あたり15万リクエストを処理
いま取り組んでいるのがこの図に示されたものです。
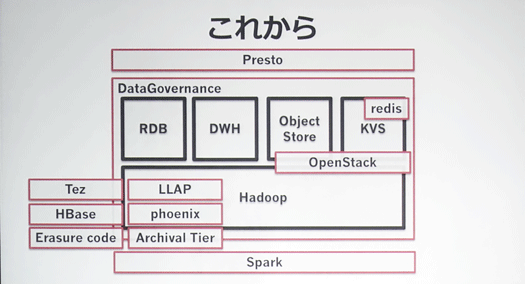
今日はHadoopまわりにフォーカスします(図左下)。
Tezの導入が本格化しており、LLAPの開発も進めており、HBaseは現在検証中、Erasure code、Archival Tierなどにも取り組んでいます。
Sparkはサイエンス部隊で検索データのグラフデータ化に試験的に取り組んでいます。
【次ページ】 データ需要の増大を、コストではなく技術で解決する
関連コンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
関連コンテンツ
あなたの投稿
PR
PR
PR
