- 会員限定
- 2015/08/13 掲載
NTTデータの猿田氏に聞く、Hadoopよりも高速かつ高機能な分散処理基盤Sparkとは?
Sparkとは何か(後編)
最近ビッグデータ処理基盤として急速に注目を集めているのが「Apache Spark」です。Sparkは、Hadoopと比較されることも多く、Hadoopよりも高速かつ高機能な分散処理基盤だと言われています。Sparkとはいったい、どのようなソフトウェアなのでしょうか? 今年6月にSparkのコミッタに就任したNTTデータの猿田浩輔氏に聞きました。
Spark内部の動作が可視化
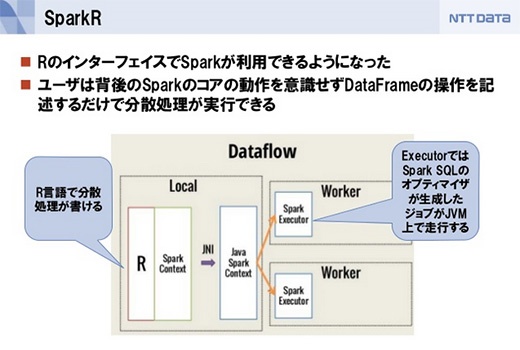
最新のSpark 1.4では、大きな機能追加が3つあります。1つは、R言語でSparkを用いた処理が書ける「SparkR」です。これもDataFrame APIが呼び出され、オプティマイザが走ります。
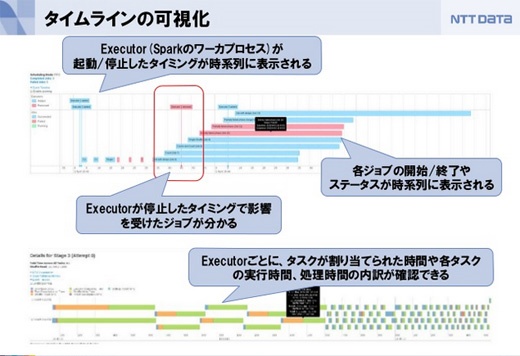
また、Spark内部の可視化が強化されました。Spark Streamingの統計情報の可視化によって単位時間あたりのデータの流量や処理のスループットが確認できますし、RDDの変換過程が可視化されたことでオプティマイザが入った変換や複雑なRDDの変換チェインの全体像が把握しやすくなり、ボトルネックなどが発見しやすくなっています。
各ジョブの開始、終了、タスクが割り当てられた時間や各タスクの実行時間、処理時間の内訳なども確認できます。例えばスレーブサーバが落ちたときにワーカーが何をしていたか、遅延がやたら大きいスレーブサーバがあるかどうか、特定のスレーブサーバに処理が集中していないか、といったことが分かります。すばやくトラブルシュートできるようになります。
「Project Tungsten」というプロジェクトが始まっていて、これはSparkの処理におけるCPUの利用効率を高めようというものです。SparkはJavaVMの上で動いているので、Javaのガベージコレクションの影響を受けます。そこでSparkに適した自前のメモリ管理によってガベージコレクションを削減したり、独自のデータ構造を持つことで無駄な中間オブジェクトの生成を省略することで効率をあげようとしています。
すでに最新のSpark 1.4で一部取り込まれています。
【次ページ】 なぜNTTデータがSparkに取り組んでいるのか?
関連コンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
関連コンテンツ
あなたの投稿
PR
PR
PR
