- 会員限定
- 2024/06/24 掲載
コンテキストウィンドウとは何か?グーグルとメタが本気、生成AI「強化」のカギ?
生成AIに欠かせない大規模言語モデル(LLM)。そのLLMの能力を「強化」させるカギとして、「コンテキストウィンドウ(Context Window)」が注目されている。グーグルやメタも、今年に入りコンテキストウィンドウに関する新技術を相次いで開発して話題を呼んだ。両社が開発した新技術とはどのようなものなのか、そして、そもそもコンテキストウィンドウは生成AIをどう強化できるのかについて解説する。

(Photo:rafapress / Shutterstock.com)
LLMの性能を左右する「コンテキストウィンドウ」とは
OpenAIやAnthropicなどが開発するLLMが、あらゆる方面で存在感を示している現在。そのLLMのパフォーマンスを左右する重要な要素の1つとして挙げられるのが、「コンテキストウィンドウ」だ。
コンテキストウィンドウとは、モデルが一度に処理できるトークン数のことを指す。トークンとは、単語、画像、動画の一部分など、モデルが扱う最小単位だ。テキストであれば、英語の場合、100トークン=75ワードほど、日本語の場合、100トークン=100文字ほどとなる。

(出典:OpenAI)
コンテキストウィンドウが大きいほど、モデルはより長い文章やより大量の情報を一度に処理できるようになる。これにより、文脈を深く理解し、整合性の取れた出力を生成できるようになるのだ。
主要なLLMのコンテキストウィンドウサイズを比べてみると、Anthropicの「Claude 3」が最大で20万トークン。OpenAIの「GPT-4 Turbo」が12万8000トークン、グーグルの「Gemini 1.5 Pro」が12万8000トークンとなっている。1年ほど前まで、主要モデルのコンテキストウィンドウが4000トークンほどだったことを考えると、最近のコンテキストウィンドウサイズの拡大は目を見張るものがある。
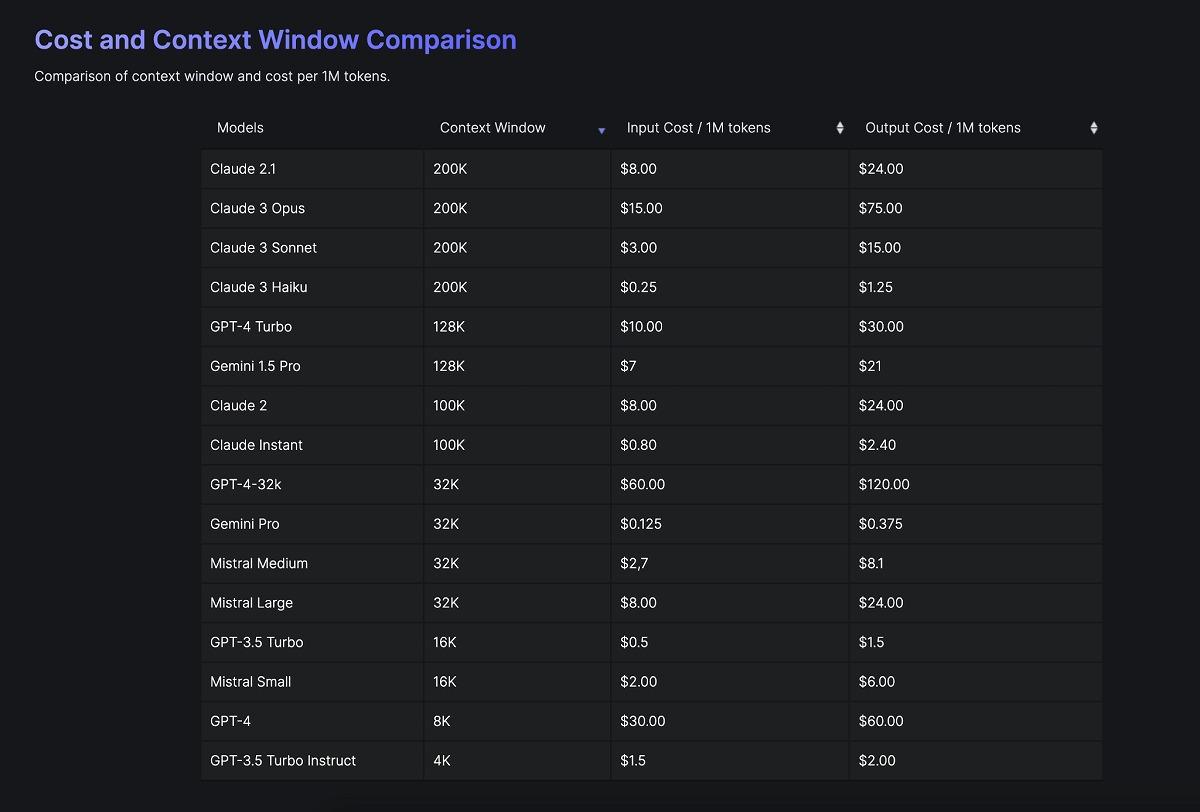
(出典:Vellum AI)
コンテキストウィンドウは、実質的にプロンプトに入力できる情報量ということになるが、より厳密にいうと、入力トークン、出力トークン、制御(システム)トークンすべてを含む情報量となる。
拡張による「3つ」のメリット
コンテキストウィンドウを拡張できれば、LLMの性能と応用可能性が大きく広がる。
第一に、より長い文章を一度に処理できるようになる。たとえば、数千ページに及ぶ長大な文書を要約したり、数万行のソースコードを解析したりといったタスクが可能になるのだ。
第二に、複数の情報源を組み合わせて活用できるようになる。LLMに文法書と用例を与えれば、わずか200人しか話者がいない「カラマン語」を、初心者と同レベルで英語に翻訳できるようになるとされる。
第三に、必要な情報をその場で学習し、文脈に応じて知識を使い分けられるようになる。グーグルの研究チームは、45分の映画「キートンの探偵学入門」をLLMに「視聴」させ、内容に関する質問に正確に答えさせることに成功した。
コンテキストウィンドウの拡張は、カスタムアプリケーションの開発にも大きな影響を与える。これまでは、特定のタスク向けにLLMを最適化するには、ファインチューニングやRAG(Retrieval Augmented Generation)など、高度なエンジニアリングが必要だった。しかし、無限大のコンテキストウィンドウを持つLLMであれば、必要な情報をすべてプロンプトに入力し、最も関連性の高い部分を選択させることが理論上可能になる。
これにより、開発者や企業は素早くアプリケーションのプロトタイプを作成し、アイデアを検証できるようになるなど、PoC(Proof of Concept)段階での障壁が大幅に下がることが期待できる。もちろん、実際に製品化する際は、コストや速度、精度などを最適化する必要がある。 【次ページ】グーグルとメタの「新技術」とは
関連コンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
関連コンテンツ
あなたの投稿
PR
PR
PR
