- 会員限定
- 2024/04/16 掲載
オープンソース大規模言語モデルまとめ、メタのLlama 2が「超重要になる」ワケ
オープンソースのLLM(大規模言語モデル)がこれまでにないほど大きな注目を集めている。OpenAIのGPTモデルなどクローズドな大規模言語モデルが圧倒的なシェアを有する状況だが、それらに匹敵するオープンソースのLLMの開発が進んでいる。メタの「Llama 2(ラマツー)」を筆頭に、日本でもそれをベースにした日本語LLM「ELYZA-japanese-Llama-2-13b」が公開された。直近ではメタに対抗して、Databricksも「DBRX」をリリース。オープンソースLLMとは何か、クローズドモデルに比べてどのような利点があるのか。オープンソースLLMが注目される理由を探ってみたい(追記:最新のLlama 3(ラマスリー)については別記事を参照のこと)。
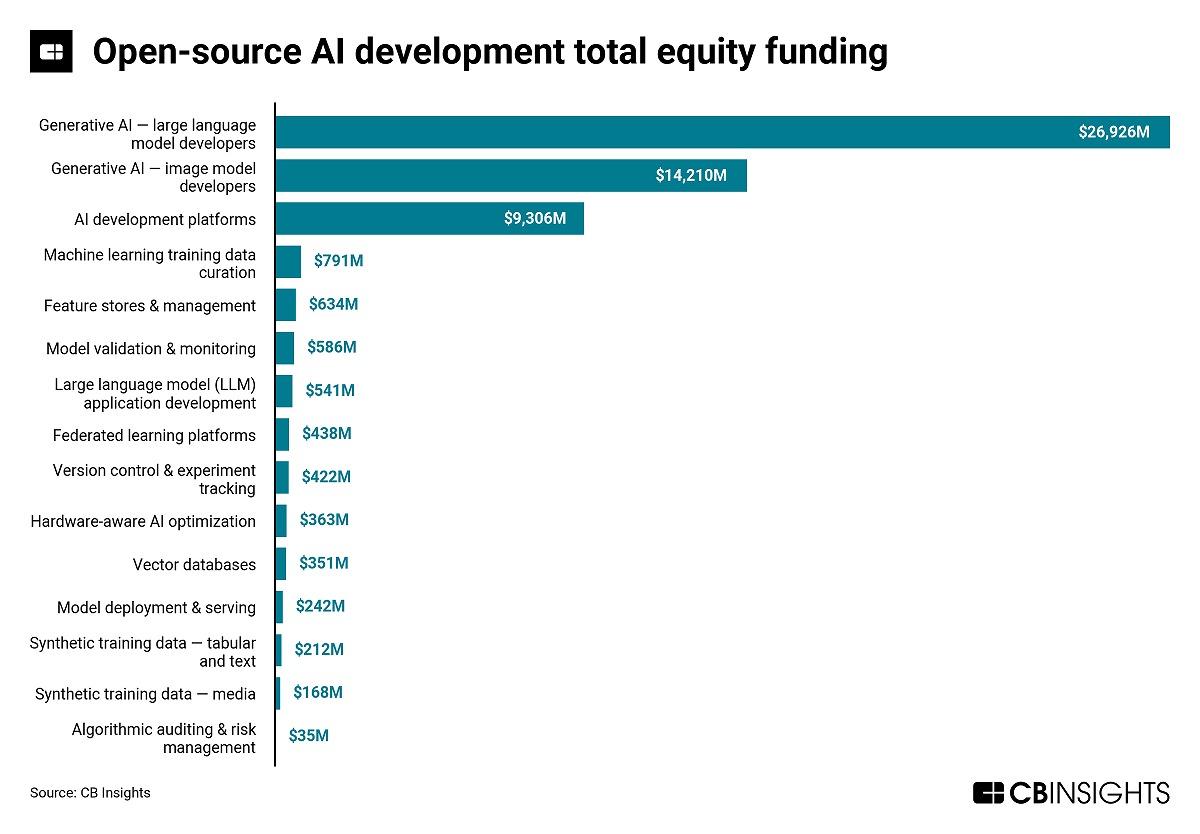
(出典:CBInsights)
オープンソースのLLMが注目される理由
2023年はChatGPTを筆頭にコンシューマー向けの生成アプリケーションが広く普及した年となった。一方、企業における生成AI利用は大きく2つのアプローチにより進展する見込みだ。1つはOpenAIやAnthropic(アンソロピック)などのAI企業が提供するクローズドLLMを活用するアプローチ。もう1つはメタやMistralなどが提供するオープンソースLLMを活用するアプローチだ。
それぞれに一長一短があり、多くの企業ではリスクを回避するために単一のLLMに依拠するのではなく、クローズドとオープンソースモデルを含め、複数のモデルを採用するシナリオが優勢となっている。
代表的なクローズドLLMは、OpenAIのGPT-3.5、GPT-4、アンソロピックのClaude 3のほか、グーグルのGeminiやCohereが提供するモデルなどが含まれる。これらクローズドモデルの長所は、オープンソースモデルに比べて簡単に利用できる点、有害なアウトプットを制限するガードレール機能、高度な技術サポート、そしてパフォーマンスの安定性などが挙げられる。
一方、オープンソース領域では、メタのLlama2、フランスのAIスタートアップMistralのMixtralモデル、アラブ首長国連邦(UAE)で開発されたFalconモデル、MosaicMLのMPTモデルなどが人気を集めている。直近ではエンタープライズソフトウェア企業のDatabricksがDBRXをリリースした。さらにはイーロン・マスクのxAIもGrokの最新版 Grok-1.5を発表している。
これらオープンソースモデルの主な利点としては、カスタマイズの自由度が高いこと、そしてモデル使用料が無料または低コストであることが挙げられる。
現在、多くの企業では、クローズドLLMとRAG(Retrieval Augmented Generation)、ファインチューニングを組み合わせた方法が主流となっている。
OpenAIのGPT-3.5やGPT-4、またアンソロピックのClaude3などのクローズドモデルは広範におよぶ知識を有しているが、特定の企業に関する詳細情報を持っていない。
このため、社内・社外向けに関わらず、企業がクローズドLLMをベースとする生成AIアプリケーションを開発したとしても、そのアプリケーションは企業に関する詳細な回答を生成することができない。
RAGのアプローチを採用することで、モデルのコンテクストウィンドウに関連情報を注入することが可能となり、企業の文脈に沿った回答を生成できるようになるのだ。
RAGはLLMをファインチューニングすることなく、比較的簡単に企業文脈に沿った生成AIアプリケーションの開発を可能とすることから人気のアプローチとなっている。しかし、やはり企業独自のデータを用いてLLMをファインチューニングしたいという需要も高まっており、こうした取り組みも増えつつある状況だ。
クローズドモデルの中でファインチューニングできるモデルの1つがOpenAIのGPT-3.5だ。AIエンジニアであるサム・ルリエ氏がGPT-3.5とコード生成に特化したオープンソースモデルCode Llama 34Bのファインチューニング比較実験を行ったところ、GPT-3.5のトレーニングコストはCode Llama 34Bに比べ3.6~6倍かかることが判明した。
ファインチューニングの結果、GPT-3.5のパフォーマンスはCode Llama 34Bを上回ったものの、その差はわずかなもので、コスト差を正当化できるものではなかったという。
またルリエ氏は、GPT-3.5のファインチューニングでは、すべてのパラメータを調整する手法ではなく、一部のみを調整する手法が採用されている可能性が高いと指摘しており、カスタマイズ性は高くないことが示唆されている。
オープンソース生成AIモデル開発の主要プレイヤー
オープンソースLLMの開発でも代表格となる企業がいくつか存在するが、まず名が挙がるのはメタだろう。メタが2023年7月にリリースした「Llama2(ラマツー)」は、OpenAIなどのクローズドモデルに匹敵するともいわれ、企業やAI開発コミュニティではLlama2をベースとするアプリケーション開発が進んでいる。
ちなみに上記で言及したCode Llama 34Bは、メタがLlama2をコーディング関連のデータでファインチューニングしたコード生成特化モデルとなる。報道によると、メタのザッカーバーグCEOはNVIDIAの最新GPU・H100を35万台購入する計画とのこと。当初の報道より大幅に増えており、同社のオープンソースLLM開発はさらに加速する見込みだ。
メタと同等、またはそれ以上の注目を浴びているのがフランスのスタートアップMistralだ。2023年5月に設立された非常に新しい企業だが、すでに数億ドルを調達し、評価額も20億ドル近くに達したといわれている。
Mistralの強みは、サイズを抑えつつ高いパフォーマンスを持つAIモデルを開発できる点にある。同社が2023年12月にリリースした「Mixtral 8×7B」は、実質的なパラメータを120億に抑えつつ、700億パラメータを持つメタの最高峰モデル「Llama2 70B」を超えたとされる。
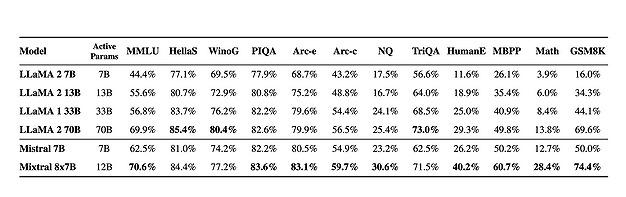
(出典:Mistral)
このほか動向が注視されるオープンソースLLM開発企業・組織としては、HuggingFace、Falconモデルを開発するTechnology Innovation Institute(TII)、MPTモデルを開発するMosaic MLなど含まれる。
さらに、Databricksも2024年3月に大規模LLM「DBRX」をリリース。オープンソースベンチマーク「Gauntlet」では30以上の異なるベンチマークが含まれており、「DBRXはそれらすべてを上回る性能を示している」という。
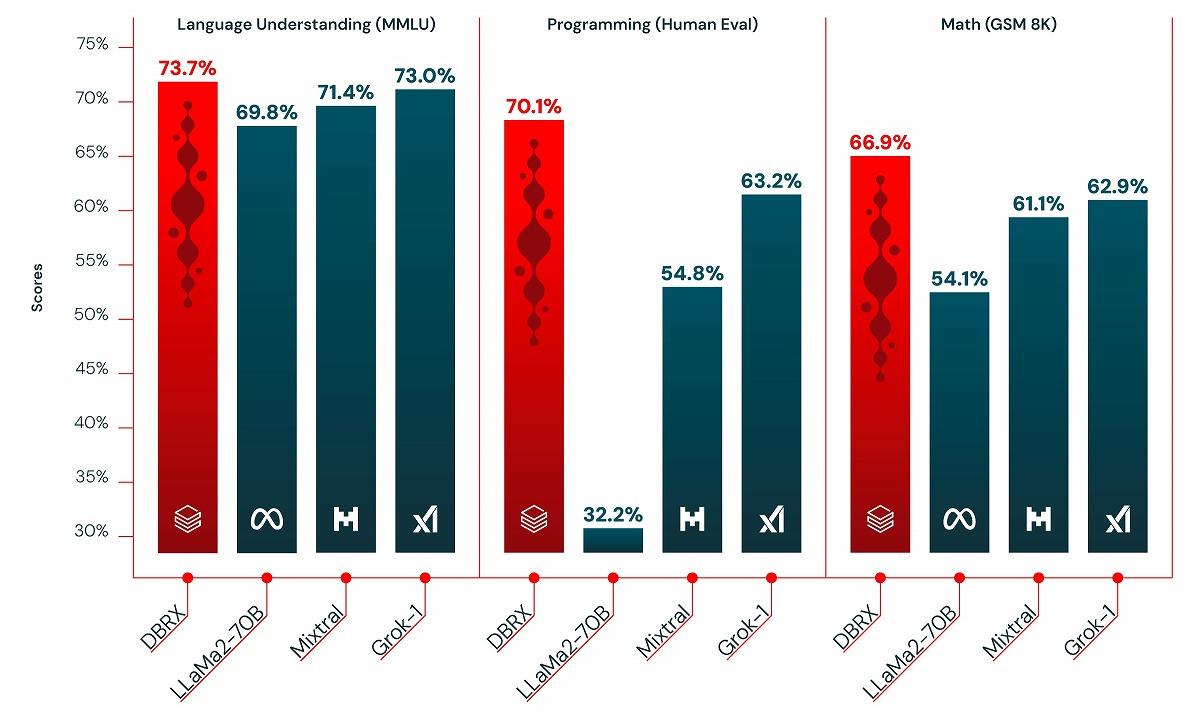
(出典:Databricks)
そのほか、イーロン・マスクのAI企業、xAIが2024年3月にオープンな大規模LLM「Grok-1.5」をリリースすると発表。一部のコード生成能力では、GPT-4を上回るスコアを獲得したと主張している。
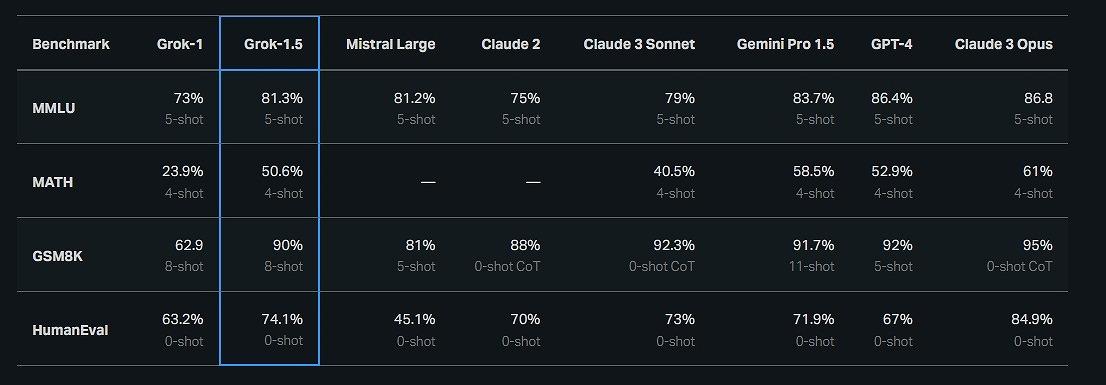
(出典:xAI)
関連コンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
関連コンテンツ
あなたの投稿
PR
PR
PR
