- 会員限定
- 2011/08/09 掲載
ビッグデータで留意するべき4つのポイントとその取り組み方--ガートナー 堀内秀明氏
「Hadoop」と「インメモリ処理」でビッグデータを使いこなす
昨今、「ビッグデータ」というキーワードが、さまざまなメディアでとり上げられている。直訳すれば「大きなデータ」ということになるが、ガートナーでは「今後ますますデータが豊富になっていく環境における情報量の飛躍的な増加、可用性、利用環境を表すために広く使われている言葉」と定義している。実際の調査でも世界のデータ量は年間約6割超のスピードで増加し続けていく見通しだ。情報爆発の時代に、企業は今後ビッグデータとどのように向かい合っていけばいいのか。ガートナー リサーチ バイス プレジデントの堀内秀明氏の提言をレポートする。
ビッグデータの活用時に留意すべき4つのポイント
ビッグデータとは何か。まず第一にインターネット上に存在する大量のデータが挙げられる。日々これらの情報は増え続けており、その中からユーザーが自力で有益な情報を見つけ出すことは非常に困難だ。そこで検索エンジンが登場した。企業内に目を向けた場合でも状況は同じで、システムの更改や構築が繰り返され、データの規模は拡大し続けている。さらにネットワーク環境が整備されたことで、携帯電話や自動販売機などからもデータは入手できるようになった。ネット上と同様に、散在するビッグデータの活用は大きな課題となっている。
こうした現状を踏まえ、「ガートナー ビジネス・インテリジェンス&情報活用 サミット 2011」で登壇したガートナー リサーチ バイス プレジデントの堀内秀明氏は、「ビッグデータの活用を考える上で、注目すべき4つのポイントがある」と指摘する。これは言い換えれば、今現在、データを管理/活用していこうとする時に意識すべき4つの側面だ。
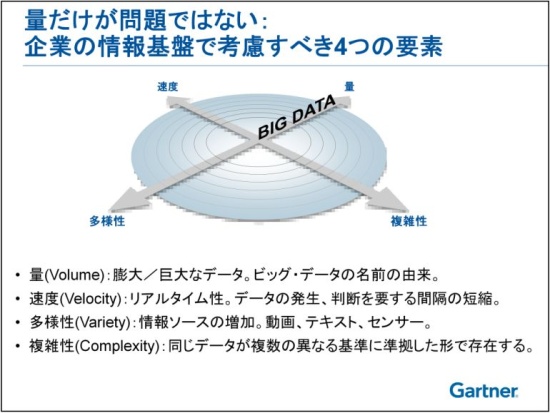
(出典:ガートナー,2011)
まず1つめが、量(Volune)だ。量が大きいというのが、狭義の意味でのビッグデータということになる。もちろんこれは重要な要素だが、過大に着目されているふしがあるため、2つめ以降の要素も同時に考慮していく必要がある。
2つめが、速度(Velocity)。データが生成される速度もあるが、より重要なのは、“そのデータを判断材料にすべきタイミング”の速度だ。
「どれだけ速く意味のある形でデータを利用者に提供できるかという視点も含んでいる」(堀内氏)
たとえば少し前なら月次でよかったものが、今では日次データが必要だという場合も少なくない。その際には、データ管理の運用方法なども考え直さなければならない。また、天候や地震、政治や経済など、時々刻々と変わっていくデータから、確固たる事実を導き出す必要性が以前にも増して高まっている。
そして3つめが、多様性(Variety)だ。多くのIT部門の担当者が一番馴染みのあるデータはRDBMSなどの構造化データだろう。一方で、それ以外にも企業内にはExcelや電子メールなどの営業系データ、さらに最近では、顧客サービスを考える上で用いられるTwitterやFacebookなどのソーシャルメディアのデータも企業にとって無視できないものになりつつある。
最後の4つめが、複雑性(Complexity)だ。現在の企業では、そもそもデータがどこにあるのか分からない、あるいはあるのかないのかさえ分からない、仮にあったとしてもそれが唯一のものなのか保証ができない、といった状況が生まれている。また、複数のシステム間でマスタデータがバラバラだったり、あるいはデータが欠損していたり、不足していたりするケースも見受けられる。
「IT部門が実は一番困っているのは、このデータの複雑性」(堀内氏)。
この状況下で手元にある情報を何らかの判断材料とするためには、たとえばExcelとPowerPointを駆使するなどして、属人的な加工を施す必要がある。
こうしたビッグデータの4つの特徴を理解した上で、企業はどのように情報利用を進めていけばいいのか。
【次ページ】ビッグデータへの取り組み方
関連コンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
あなたの投稿
PR
PR
PR
