- 会員限定
- 2021/10/18 掲載
スクレイピングとは何かやさしく解説。違法?クローリングとどう違う?
データ分析やAI技術に進歩するにつれて「データ収集」にも関心が集まるようになりました。そこで、自社に十分なデータの蓄積がない場合にも簡単に使える「スクレイピング」(Webスクレイピング)と呼ばれるデータ収集法が注目されるようになっています。しかし、スクレイピングは一歩間違えると迷惑行為や違法行為にもなり得る手法であり、正しく理解した上で扱わなければいけません。本記事ではそんなスクレイピングについて誰にでもわかるように解説していきます。
(Photo/Getty Images)
▼この記事を動画・音声でご覧いただけます▼
スクレイピングとは?クローリングとの違いは?
スクレイピング(Scraping)は「こする」「かき集める」といった意味を持つ「Scrape」に由来する用語で、物を解体する「Scrap」と似ていますが別の単語です。「Scrape」は広範囲をゴシゴシこすりながら物をきれいにしたり、散らばった物を集めたりするニュアンスが近いでしょう。そこからコンピュータ用語に転じて、特定の目的を持ってWebやデータベースを広く探って「データを抽出する手法」のことを指すようになりました。また、同じくWeb上で行われる情報収集手法に「クローリング(Crawling)」があります。こちらは「はい回る」という意味の「Crawl」から来ている用語でWeb上を広く移動しながら「巡回する手法」のことを指しています。どちらもコンピュータプログラム(ボット)を使って自動的に行われるもので、動作としては似通っています。
しかし、スクレイピングが「特定の情報を抽出する」のに対し、クローリングは「巡回してWebの構造や要素を探る」点で大きな違いがあります。Webサイトの構造を把握することは情報の抽出には必要不可欠です。そのため、大規模なデータ収集プロセスでは、スクレイピングとクローリングは同時に行われることも少なくありません。クローリングでWebサイトの構造や状態を把握しつつ、ついでに必要な情報をスクレイピングで集めるというイメージです。そのため、実際にはクローリング用のツールでスクレイピングまでできてしまうことが多いです。
営業マンの活動に例えるなら、営業マンが車や徒歩で市街地を周りながら表札を確認して地図を作るのがクローリングで、そこでインターホンを押して「◯◯さんいますか?」と住人の顔と名前を確認して回るのがスクレイピングと言えるかもしれません。いわばクローリングは広く浅く素早く探る技術で、スクレイピングは広く探りつつ要所で深く探る技術をイメージすると良いでしょう。
スクレイピングの仕組みを図解
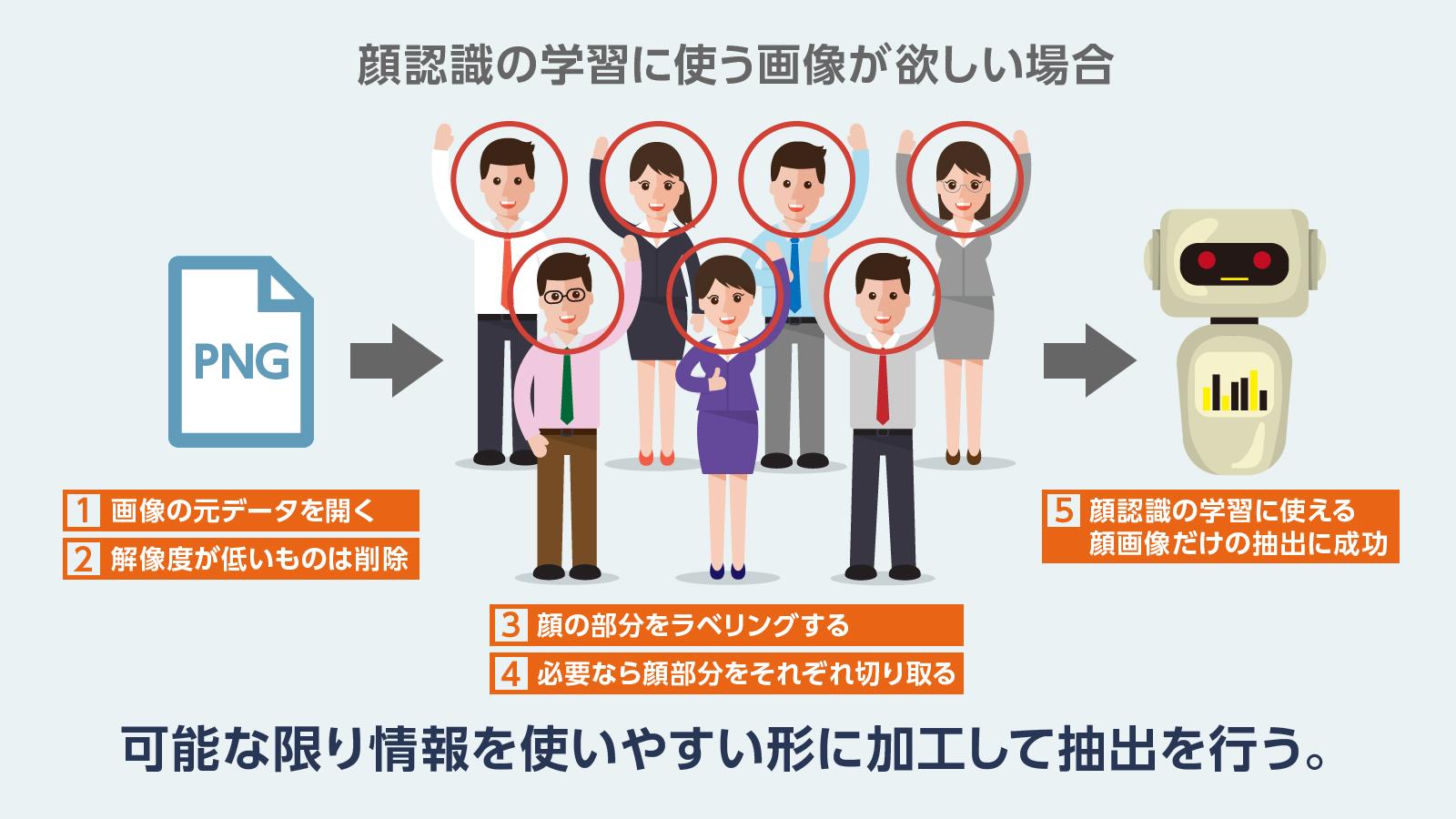
大まかなイメージをつかめたところでスクレイピングについて、もう少し詳しく見ていきます。スクレイピングでは、最初に「どんな情報が欲しいか」ときちんと定義します。それは本当に場合によりけりで「商品の価格」「新製品」「検索の順位」「単語の出現率」「評価・評判」「学習データ」など、アクセス可能なデータのほとんどがスクレイピングの対象となり得ます。そして、欲しい情報が定義されたら、その情報がWebサイトやデータベースのどの部分に記載されているのかを突き止め、情報が記載されている可能性のあるページなどを自動的に周って情報を抽出します。このスクレイピングにおける「抽出」は有用な情報として利用するために、不要な情報を削ったり補足をしたりといった「加工」も含むプロセスで、ただ情報を集めるだけではなく有用な形で収集することに重点が置かれる点がスクレイピングの特徴です。
ちなみに、情報が時間によって変動したり増えたりする場合には、当然ながら定期的にチェックすることになります。この場合、少しややこしいですが定期的な巡回は多くの場合「クローリング」として扱われます。というのも「取得したい情報があるかないか」を確認するだけなら情報を抽出するプロセスは不要だからです。
新しい情報があればスクレイピングで抽出し、新しい情報があるかないかはクローリングで確認するということです。先ほどの例で言えば、営業マンが昨日巡回(クローリング)している時には電気が点いていなかった家が今日は電気が点いていたので、インターホンを押して情報を収集(スクレイピング)するというイメージです。
また、AIの学習データのように必要なデータの識別に人間のチェックが必要な場合、ある程度手作業(半自動)でスクレイピングをすることもあります。何人かのワーカーが必要な情報を大まかに定義し、WebサイトやSNSをチェックしながら定義された情報をピンポイントで抽出します。最終的には自動化をしますが、自動化に必要な厳密な定義が定まっていない場合やアルゴリズムの簡単な確認作業をする際には有用な方法です。
【次ページ】スクレイピングの注意点、「業務妨害」扱いされてしまう?
関連コンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
関連コンテンツ
あなたの投稿
PR
PR
PR
