- 会員限定
- 2021/02/03 掲載
検索エンジンにおけるクローラーの役割、ソフトウェアエージェントとは
連載:図でわかる3分間AIキソ講座
ビッグデータや人工知能(AI)、ロボティクスの発展の裏には、実は「エージェント」の存在があります。ここで言う「エージェント」とは、転職やスパイの話ではなく、ユーザーや管理者の意図に沿ってさまざまなタスクを勝手にこなしてくれる“プログラム”のことです。このエージェントは、私たちの知らないところで重要な役割を果たしています。そうした、エージェントの働きを理解しておくことで「機械が勝手にやってくれる」プロセスの謎の1つが明らかになります。
情報理論における「エージェント(代理人)」とは
エージェントは「代理人」という意味の単語で、雇い主や契約によって任されたタスクを与えられた権限の範囲で勝手にやってくれる存在を指します。身近な例を挙げるとするならば、転職エージェントなどをイメージすると分かりやすいでしょう。転職エージェントは、自分の意図や意志を伝え、希望に沿った転職先を探し、交渉してくれる存在です。理想的なエージェントなら、電話一本で転職が決まってしまうことでしょう。このように、「頼めば勝手にやってくれる代理人」の存在は、まさに人工知能(AI)などの機械やプログラムが目指す形の1つです。
今回解説する情報理論におけるエージェントとは、よく耳にするエージェントと区別するために、「ソフトウェアエージェント」と呼ばれ、普通のプログラムと違って「自律性」「永続性」「協調性」などの特徴を持ちます。言わば与えられた目的に沿って「勝手に」「継続的に」「必要な情報交換を行いながら」活動してくれるソフトウェアということです。
勝手にやってくれるだけなら普通のソフトウェアと変わりませんが、仕事が1つ終わったからと言って、そこで仕事を止め次の指示を待つということはありません。また、ほかのプログラムやデータベースと情報交換をしつつ、上手にほかと協力しながらタスクをこなしていくのもエージェントの特徴です。

(Photo/Getty Images)
勝手に作業をしてくれる「クローラー」とは
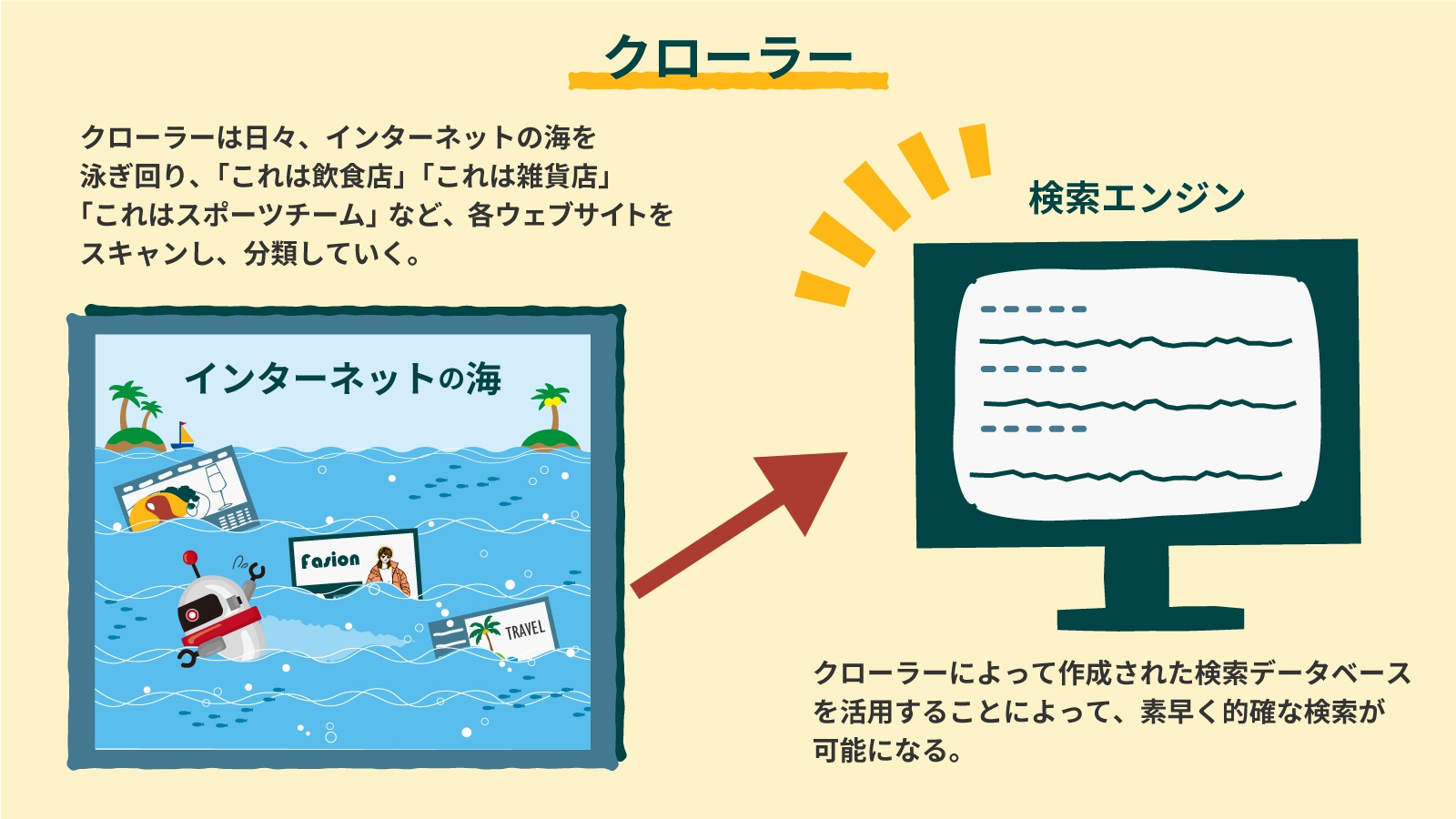
ソフトウェアエージェントによる作業の中で代表的なものに、「検索エンジン」がページの索引(インデックス)を作る作業があります。この作業を実行するのが「クローラー(這い回る者)」と呼ばれるソフトウェアエージェントです。具体的に何をしているかというと、世界中のウェブページをスキャン・解析し、自動的にインデックスのデータベースを作成してくれます。日々、インターネット上の情報は増え続けていますが、それに対して人間がいちいち作業をする必要はなく、インターネットの海を自動で巡回するクローラーがインデックスを作成してくれます。
このクローラーが、まさにソフトウェアエージェントであり、ビッグデータを利用するためには無くてはならない存在なのです。また、変化し続ける情報ネットワークにおいては、環境に適応して変化する能力も必要です。機械学習技術などを応用し、自ら学習して成長する「知的エージェント」と呼ばれるエージェントも登場しています。
勝手に成長して、勝手に通信して、勝手に作業を行い続けるプログラムというと、まるでSF映画まるでSF映画に登場する攻撃マシンのようですが、現実はもっと地味です。
たとえば、データマイニングにも知的エージェントは利用されていますが、エージェントは延々と分類作業を続け、機械学習によって分類の精度を上げながらひたすら分類作業を続けるだけです。書類整理の精度を上げるために学習するエージェントに対し、ストライキや賃上げ交渉の心配をするのは杞憂かもしれません。
「マルチエージェント」とは
ここまで説明した知的エージェントを複数組み合わせたものが「マルチエージェント」です。たとえば、前述したクローラーは複数のエージェントによって構成されています。クローラーを構成するエージェントには、ウェブサイトや変更を検知するエージェントもあれば、インデックスを作って検索精度を上げるエージェント、ウェブサイトの危険性や内容をチェックするエージェント、などが組み合わされています。
このように1種類のエージェントが、なんでもこなしてくれるわけではなく、必要な処理をこなせるよう複数のエージェントを組み合わせることがあります。
【次ページ】高度な処理を可能にする「包括アーキテクチャ」とは
関連タグ
タグをフォローすると最新情報が表示されます
関連コンテンツ
あなたの投稿
PR
PR
PR
