- 会員限定
- 2019/02/18 掲載
「ようやく実現できた」眼球運動のAI化を巡るハッカソン、かつてない高レベルに
第4回全脳アーキテクチャ・ハッカソン
全脳アーキテクチャ・イニシアティブ(以下、WBAI)の主催により、3日間にわたって開催された「第4回全脳アーキテクチャ・ハッカソン」。今回は「AIにまなざしを」をテーマに、眼球運動のタスクを解く計算モデルの構築を計7チームの有志が競い合った。前編では、競技の背景、眼球運動の種類、実装モデル、競技タスク、評価基準などについて説明した。後編は、いよいよ成果発表会だ。ここでは、特に優秀な成績を収めたチームを中心に紹介したい。

前編はこちら(※この記事は後編です)
個人参加ながら、各タスクで高得点をたたき出した初参加の優勝者
前編でも触れたが、今回のハッカソンのテーマ「AIにまなざしを」を改めて確認しておこう。これはWBAIから提示された脳のアーキテクチャと制約条件の下で、眼球運動に関する6つの視覚タスクを単一の計算モデルで解くこと、すなわち、脳のように眼球運動を生み出す計算モデルを構築することを目指すというものだ。WBAIから参考に提示されたアーキテクチャの全体像は以下のとおりになる。
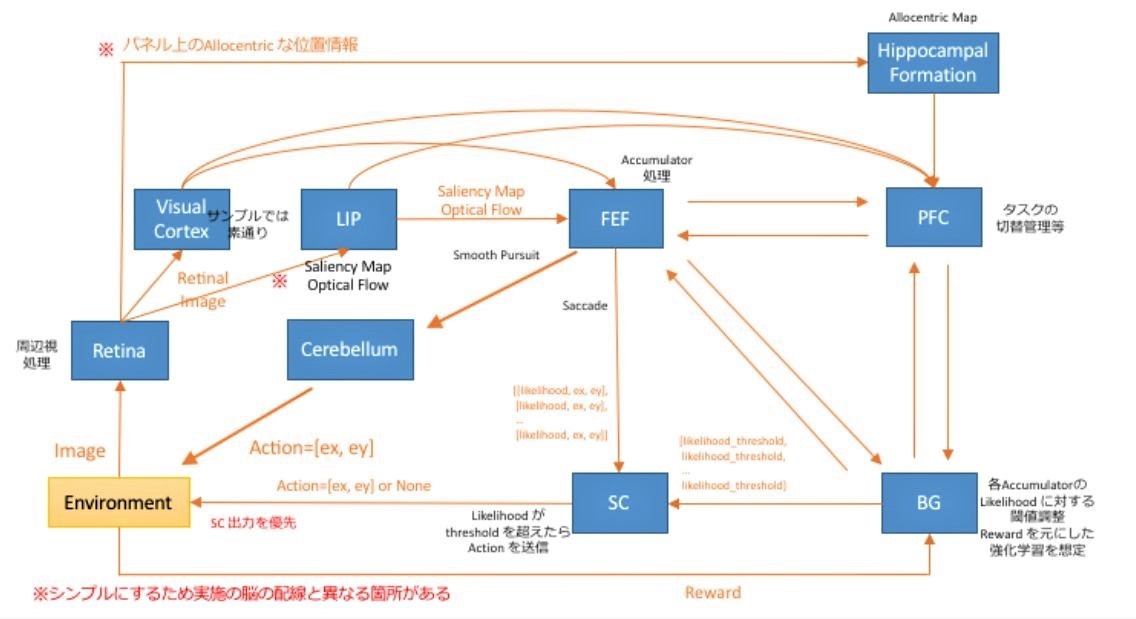
ここからは、優秀な成績を収めたチームの発表内容について簡単に触れていく。
【最優秀賞】WIPの太田 晋氏が大健闘! ダントツの高得点で栄誉に輝く
各タスクで高得点を取り、栄えある「最優秀賞」に輝いたのは、個人参加の太田 晋氏(チーム名:WIP)だ。

関連記事
太田氏は「モデルの設計方針として、並列性、積分、時間軸、記憶をキーワードにしました。まずアーキテクチャを階層的・並列的とし、構成モジュールの結合を疎にして、個別に学習させました。モジュールを跨いだバックプロパゲーションを行わず、非同期分散の計算をやりやすくする方針を採りました」と説明する。
また、WBAIが提供したサンプルであるAccumulatorモデルによって時間積分を行い、時間軸となるステップ数と状態をもとに、タスクを3つのフェーズに分解。これによりモジュールごとにサブタスクに分け、サブゴールを学習させる流れとした。また記憶についてはワーキングメモリを用い、保持した過去の状態と現在の状態を比較することで変化を検出した。
同氏は、6つのタスクを解く際に求められる機能と、アーキテクチャ上での機能の割り振りについても整理した。
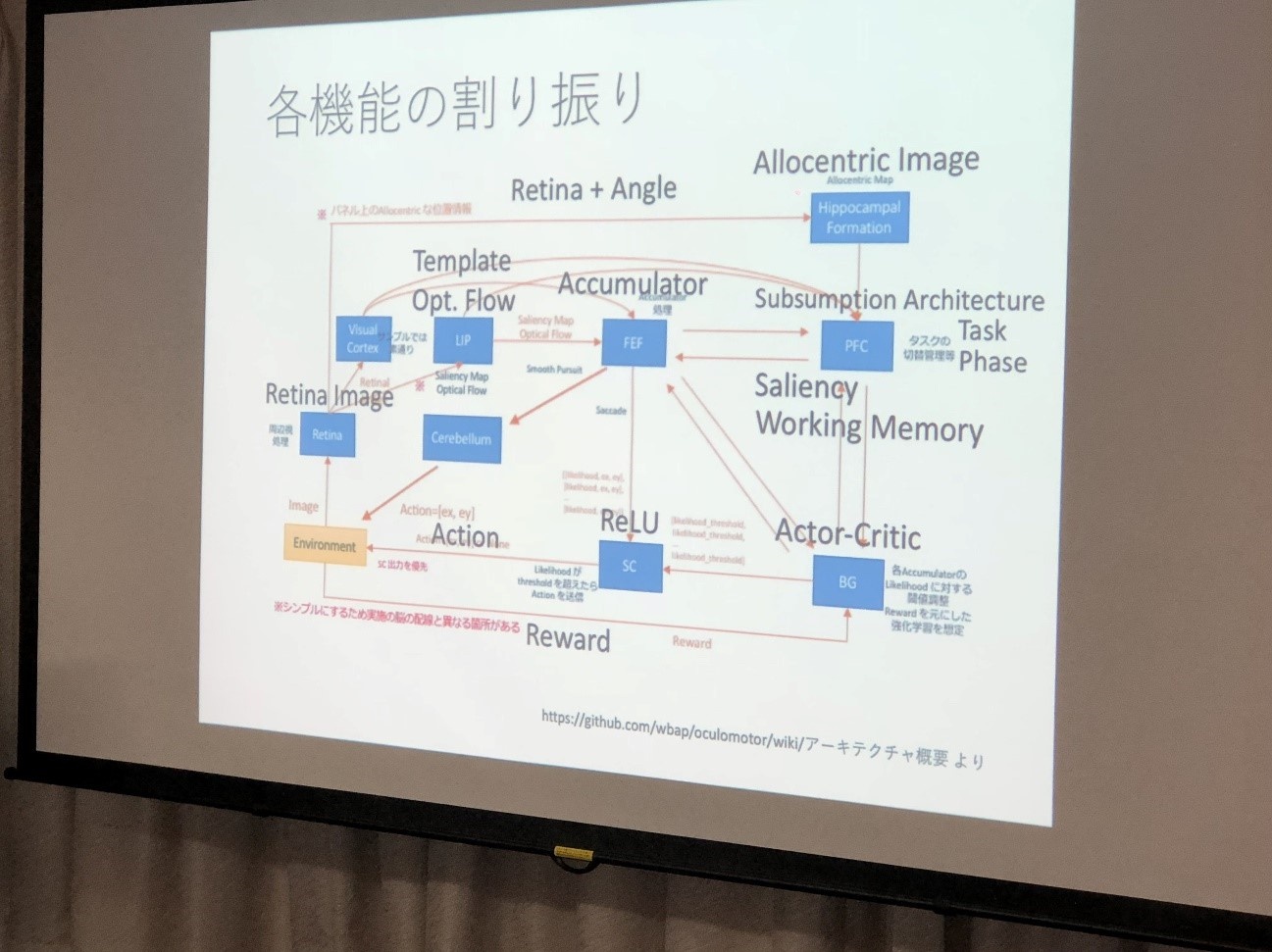
各タスクの課題を解くには、たとえばPoint to Targetでは、Saliency mapで探索しながら、対象をテンプレート・マッチングする。Change Detectionでは、変化を捉えるためにワーキングメモリに変更前の状態を保存して、変更後の状態を比較するという仕組みだ。
「初期実装では、BG(大脳基底核)の部分をルールベース(if-then)で書きました。次に6つのタスクを単一モデルで解くために強化学習ベースにすると時間がかかることが分かりました。ハッカソン期間中に学習を終えることが難しいため、今回の結果はルールベースで評価しました」(太田氏)
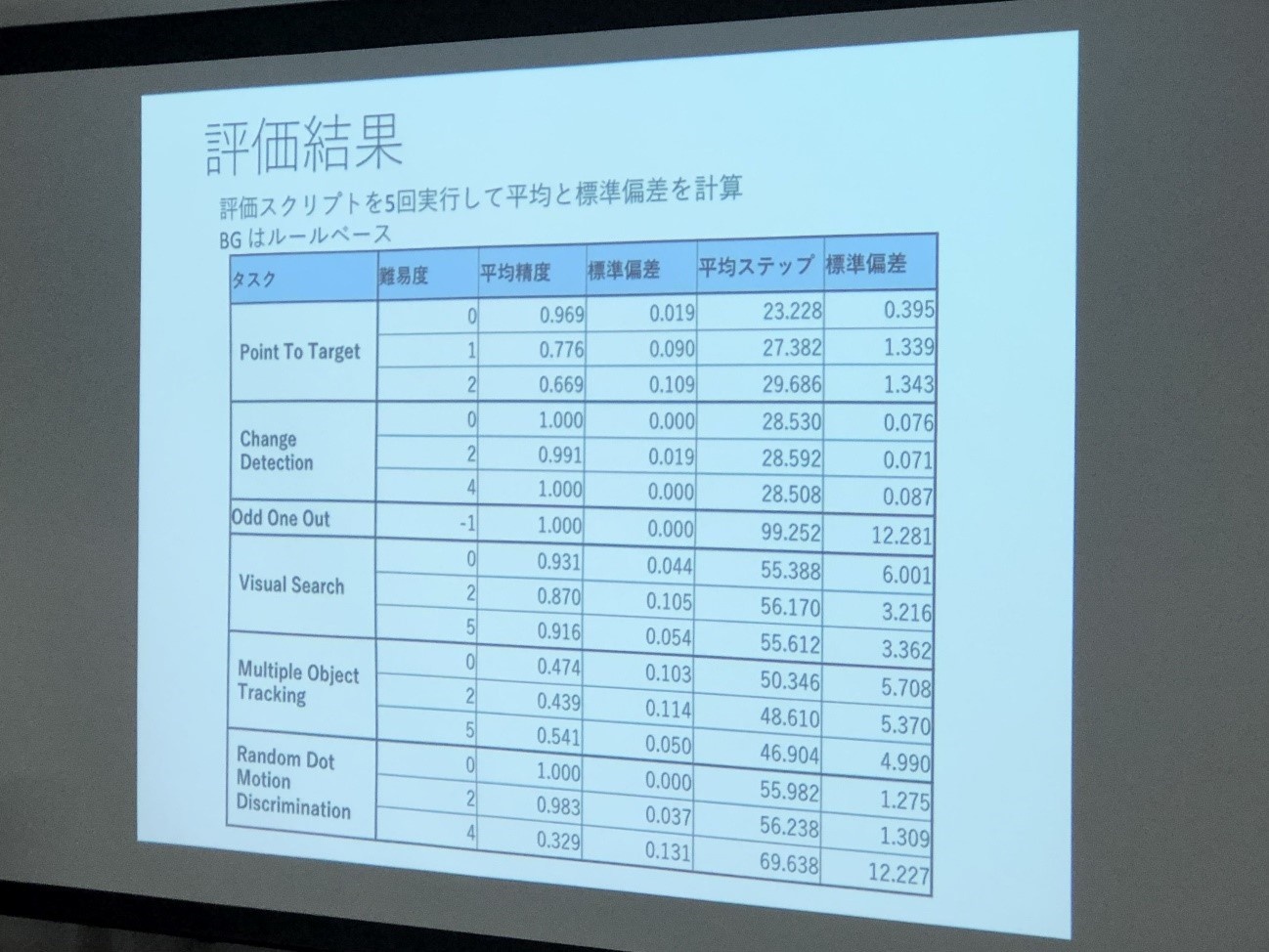
なお、Saliency mapの実装時にボトルネックが発生したので、工夫を凝らしたそうだ。視点がパネル枠に反応してしまうので、枠を取り払ったこと、また人間などの目の特性として対象の中心の周りがぼやけてしまうのだが、全体の周期性が分かりづらいため、あえて逆に中心もぼかすというアイデアを披露した。これは他チームも大いに参考になったそうだ。

「考察としては、(本テーマからは外れるが)強化学習でなく、ルールベースでもある程度はタスクが解けることが分かりました。また今回は(通常の機械学習は同期で実行するが、非同期並列でモジュールを実行する)BriCAで構築したモデル(oculomotor)の妥当性も証明できたかもしれません」(太田氏)
独自のアイデアと工夫で挑んだ3つの大学チームが優秀賞を受賞
今回のハッカソンは、ハイレベルで優劣のつけがたい結果となり、大学3チームが優秀賞に輝いた。かなり難しい課題にも関わらず、いずれのチームもオリジナルな手法を取り入れ、審査員の評価も高かった。以下、3チームの内容について簡単に紹介しよう。【優秀賞】提案モデルの数理・解剖学的な美しさを追及した東大・京大・東工大の混成チーム「Meta Limbic System」
東大・京大・東工大の友人が集まって結成された「Meta Limbic System」。当初は、メタ学習やActor-Critic系の利用を考えていたが、最終的には複数タスクに対応できる入力データを工夫することで、強化学習によるプローチを試みたという。

今回のハッカソンのタスクは、「Point To Target」「Random Dot」「Odd One Out」「Visual Search」「Change Detection」「Multiple Object Tracking」という6つの種類からなるが(タスクの詳細は前編を参照)、アプローチ的に大きく2分できるという。
「前半3つのタスクは、ターゲットに眼球の視点を持っていくこと、後半3つのタスクはYESかNOで答えられるものです。後半のタスクを1つの重みで学習させるのは難しいため、汎化性能を上げるために、主に前半のタスクの解決に重点を置きました」(同チーム)
またタスクにより有効な特徴量も異なるため、タスクのラベルによって有効な特徴量を選択できる「Attention Map」を学習する方針を立てたという(学習時に複数タスクを同時学習)。これにより各タスクの特徴量の明示的ではないスイッチングを実現した。

「前半3つのタスクに関し、Point To Targetと、より複雑なOdd One Outは、Saliencyが高い部分に視点を持っていけば、基本的に問題は解決します。Random DotもOptical flowの勾配を計算し(物体の移動で生じる隣接フレーム間の動きの見え方をベクトル場で表現)、その方向に眼球を動かせば解決することが分かりました」(同チーム)
同チームが特に秀逸だった点は、Saliency mapとOptical flowを統合的に扱おうとしたこと。Optical flowの実装は各チームが苦戦した部分だった。最も複雑なタスクの「Multiple Object Tracking」も、Optical flowの計算によって解決できると考え、Optical flowのSaliency mapも作成した。

今回のモデルのアーキテクチャは以下のとおり。
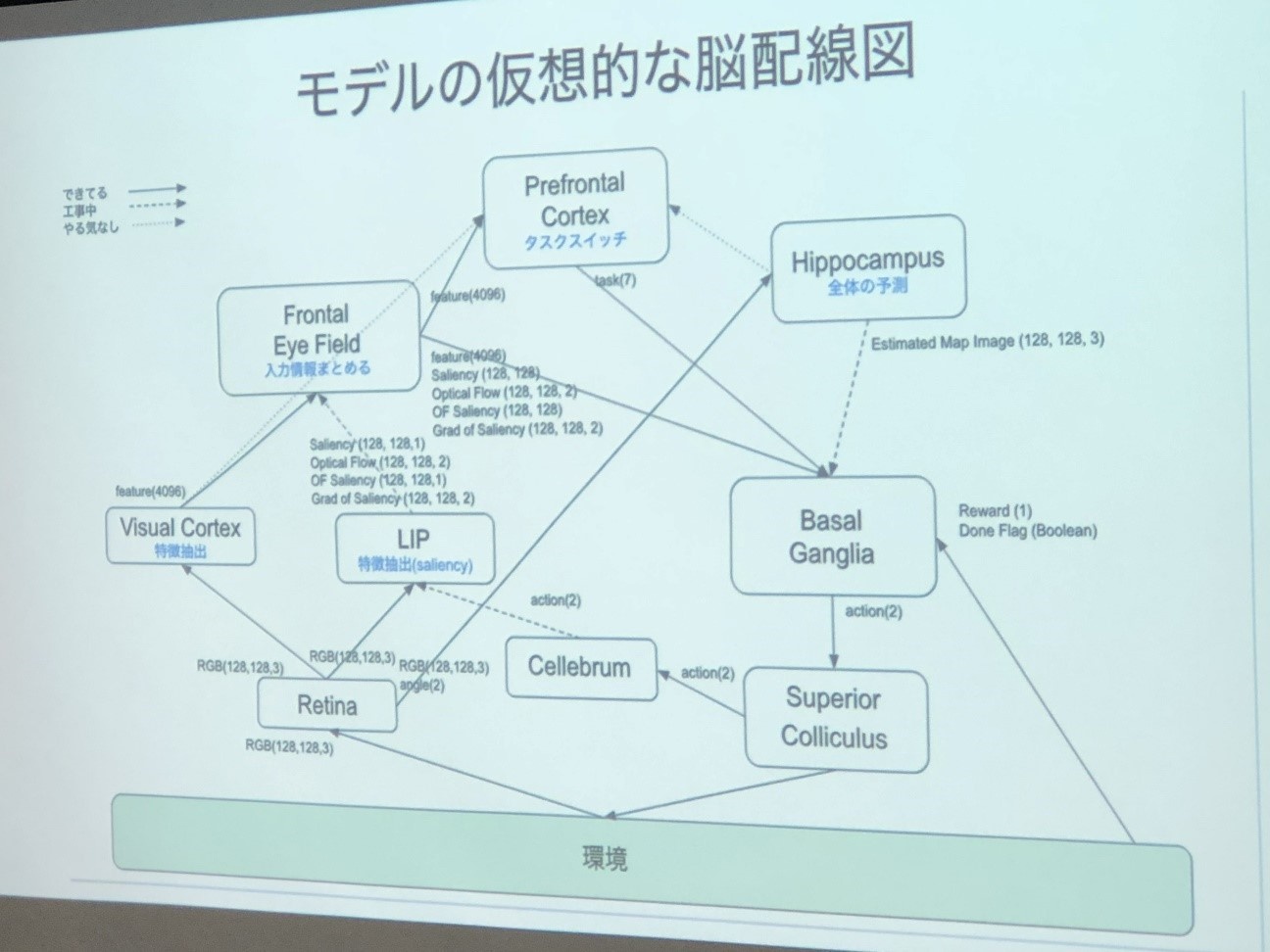
まずRetina画像から視覚部のVC(Visual Cortex)で特徴抽出し、LIP部でSaliency mapとOptical flowを生成する。これらの入力情報をまとめ、タスク検出器でタスクを判定し、学習を繰り返すという流れだ。実験結果では「Multiple Object Tracking」と「Random Dot」「Odd One Out」などの一部で成果が得られたそうだ。
同チームは「提案したモデルは脳機能的には的外れでなかったと考えています。今回のハッカソンでは、特徴量の物理的な性質の考慮や、タスクの特徴分析が大切でした。また提案モデルの数理や解剖学的な美しさを追いかけても、動かなければ意味がないため、タスクファーストでモデルを考えることが重要だと思いました」と競技を振り返った。
【次ページ】昨年に引き続き、高い評価を得た慶應義塾大学チーム
関連コンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
関連コンテンツ
あなたの投稿
PR
PR
PR
