- 会員限定
- 2024/01/25 掲載
ベクトルデータベースとは何かを図解、生成AIで「必須の存在」はどんな役割を担うのか
生成AIの可能性を広げる「ベクトルデータベース」への関心が急速に高まっている。ベクトルデータベースとは、生成AIが扱う非構造化データの格納・管理・照会で利用されるデータベースのこと。ここではベクトルデータベースの基本をわかりやすく解説するとともに、リレーショナルデータベースとの違い、生成AIの普及において、どのような役割を果たすのか、注目される理由などと合わせて紹介しよう。
ベクトルデータベースとは何か?
今後2~3年かけて企業における生成AI活用が急速に増えると予想される中、「ベクトルデータベース」への注目度が高まっている。ベクトルデータベースとは、生成AIが扱う非構造化データ(テキスト、画像、音声など)の格納・管理・照会で利用されるデータベースで、企業が自社データを活用した生成AIアプリケーションを開発する際に必須となるインフラだ。
企業で最も普及している生成AIユースケースの1つとして、社内データを大規模言語モデルに読み込ませた社内向けカスタマイズチャットAIが挙げられる。たとえば、OpenAIのGPT-3.5やGPT-4モデルなどに社内データを与え、社員が社内データから必要な情報やインサイトを取得できるシステムを開発する動きが増えつつある。マッキンゼーが社内で展開しているLilliはその好例といえるだろう。
基本的にOpenAIのGPTモデルなどは、ネット上の公開データをもとにトレーニングされたもので、社内データなどの非公開データに関する知識は持ち合わせていない。この不足を補うために、企業の社内データをAIモデルに与え、AIモデルが企業の特定文脈に沿った回答を生成できるようにするシステムを開発する動きが増えつつあるのだ。
このアプローチは「Retrieval Augmented Generation(RAG)」と呼ばれ、国内外多くの企業で採用・計画が進んでいる。
ベクトルデータベースは、このRAGアプローチにおいて非常に重要な存在であり、ベクトルデータベースサービスを提供する企業への投資も生成AIトレンドの中で急速に拡大中だ。
MarketsandMarketsの調査によると、ベクトルデータベース市場規模は2023年に15億ドルとなり、今後23%以上の成長率を維持し、2028年には43億ドルに拡大する見込みという。
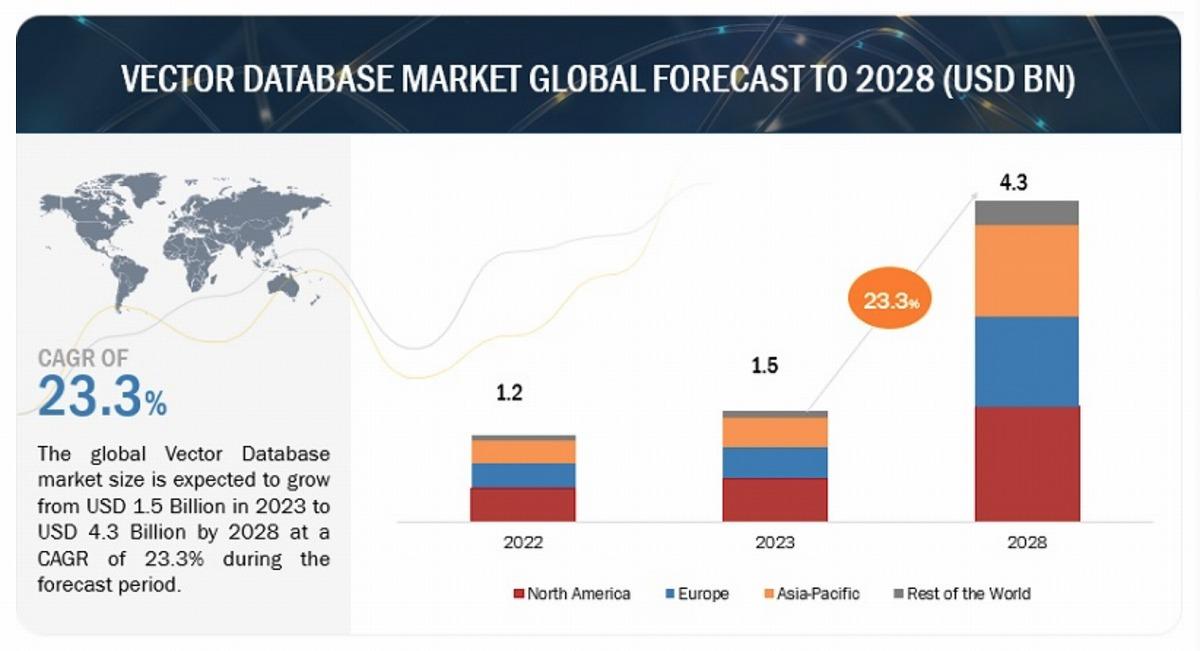
(出典:MarketsandMarkets)
従来のデータベース(SQLなど)と何が違うのか
データベースといえば、Eコマースのバックエンドやウェブアプリケーションにおけるユーザー管理などで広く利用されているSQL系のリレーショナルデータベースを指すことが多いだろう。このリレーショナルデータベースとベクトルデータベースにはどのような違いがあるのか気になるところ。リレーショナルデータベースの特徴とベクトルデータベースの特徴を比較してみたい。
まず、リレーショナルデータベースの特徴を概観したい。
データ構造は、行と列を使用してデータを表形式で格納する構造。エクセルのようなスプレッドシートのような構造だ。
クエリ言語としてSQL(Structured Query Language)を使用しデータを操作する。構造化されたデータの管理に適しており、Eコマース、トランザクション処理、顧客管理情報などで広く利用されている。
インデックスと検索では、B-treeなどのインデックス構造により、大量の構造化データを素早く検索できる仕組みとなっている。
これに対し、ベクトルデータベースはどのような特徴を持つのか。
まずデータは上記でも説明したように、ベクトル形式で格納される構造で、多次元空間の点として表されるデータ表現となる。
ベクトルデータベースのクエリは、伝統的なSQLクエリとは異なり、ベクトル間の類似性に基づいて実施される。このとき使用されるのは、ユークリッド距離やコサイン類似性など。ユークリッド距離とは、2つの点間の直線最短距離をピタゴラスの定理を用いて測定する方法。一方、コサイン類似性は、2つの非ゼロベクトル間の類似度をコサイン角度を用いて測定する。-1から1の間で変動し、ベクトル間の類似度が高いほど1に近づく。 【次ページ】具体的な活用プロセスとは?
関連コンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
関連コンテンツ
あなたの投稿
PR
PR
PR
