- 会員限定
- 2024/08/15 掲載
Florence-2をわかりやすく解説、なぜマイクロソフトの新AIは軽量でも大規模超えなのか
文章生成はもとより、画像生成から、物体検知、キャプション生成、関連質問への回答生成など、AIモデルの進化が加速している。最近特に注目されているのが、小型のオープンソースモデルのパフォーマンスが急速に高まっている点だ。マイクロソフトが最近発表した「Florence-2」は、7億パラメータと非常に小さなサイズでありながら、さまざまな大型モデルを凌駕し、AIコミュニティで高い注目を集めている。Florence-2とはどのようなモデルなのか、その特徴を解説したい。
(出典:Hugging Face)
マイクロソフトが「Florence-2」とは何か
しかし、この状況を大きく変える可能性を持つモデルが登場し、AI開発コミュニティで注目を集めている。マイクロソフトのAzure AIチームが2024年6月にリリースした新しいビジョン基盤モデル(Vision Foundation Model、Vision Language Modelとも言われる)「Florence-2」だ。
Florence-2は、さまざまなビジョンタスクを統一的かつプロンプトベースで処理できるAIモデル。画像キャプション生成、物体検出、ビジュアルグラウンディング、セグメンテーション、文字認識、などさまざまなタスクに単一モデルで対応できる点が特徴となる。
Florence-2の開発にあたり、マイクロソフトは54億件のアノテーション(テキストや音声、画像といったデータに、タグやメタデータを付ける作業)を含む大規模ビジュアルデータセット「FLD-5B」を作成し、これを用いてモデルを訓練した。このデータセットに含まれる画像は1億2600万枚に上る。
同モデルは、2億3200万パラメータと7億7100万パラメータの2つのサイズで開発されたが、いずれも小型で、ローカル環境でも十分に利用することができる。各タスクの精度も高く、遥かに大きなサイズの競合モデルと同等、またはそれ以上の性能を示すことが報告されている。
以下では、ビジョンタスクのゲームチェンジャーとなり得るマイクロソフトのFlorence-2の詳細を見ていきたい。

(Photo:Below the Sky / Shutterstock.com)
Florence-2の特徴
Florence-2の最大の注目点は、非常にコンパクトなサイズながら、数十億パラメータを持つ大型モデルに匹敵する性能を有していることだろう。このコンパクトさにより、コンシューマー向けPCなどのローカル環境でも利用可能となっている。また、多様なビジョンタスクをワンストップで実行できる点、そして商用利用可能なオープンソースとして公開されている点も特筆に値する。
Florence-2が小型でありながら、幅広いビジョンタスクに高い精度を発揮できる理由の1つは、訓練に使用されたデータセット「FLD-5B」にある。
このデータセットは、1億2600万枚の画像に対して5億件のテキストアノテーション、13億件の領域テキストアノテーション、36億件のテキストフレーズ領域アノテーションを含む、包括的なもの。これらのアノテーションは、画像レベル、領域レベル、ピクセルレベルの多様な空間階層をカバーしている。

(出典:Florence-2開発レポート)
Florence-2の訓練プロセスも興味深い。マイクロソフトは、専門モデルによる初期アノテーション、データフィルタリングによるエラー修正と不適切なアノテーションの除去、そして反復的なデータ精製プロセスを経て、高品質なデータセットを構築した。
この過程で、人間による労働集約的な手動アノテーションに頼らず、専門モデルを用いて自律的にアノテーションを生成する手法を採用。これにより、アノテーション生成の時間とコストを大幅に削減しつつ、大規模なデータセットを迅速に構築することが可能になったという。
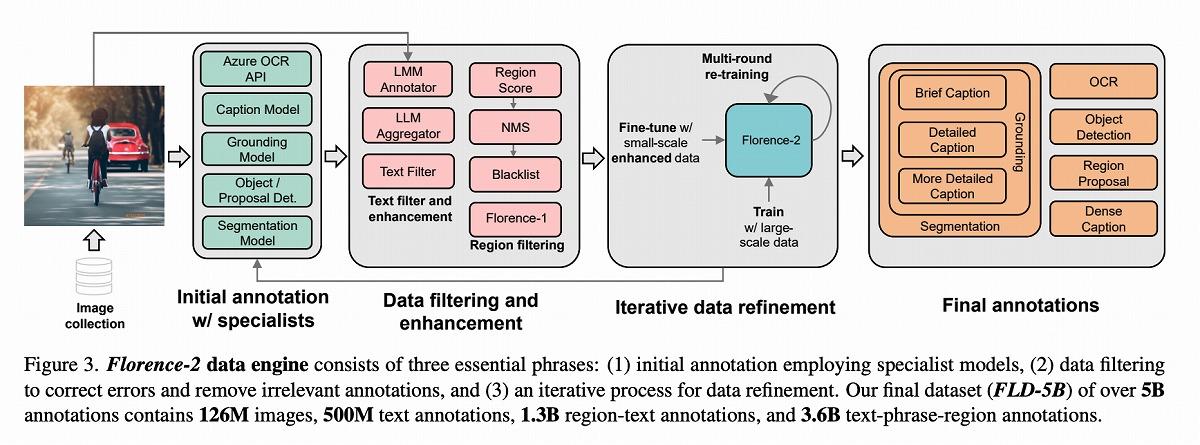
(出典:Florence-2開発レポート)
関連コンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
関連コンテンツ
あなたの投稿
PR
PR
PR
