- 会員限定
- 2024/08/08 掲載
Claude 3.5 Sonnetとは何かをわかりやすく解説、なぜGPT-4oを超えた「最強」なのか
OpenAIの競合、アンソロピックは2024年3月、大規模言語モデル(LLM)のGPT-4を超えるClaude 3 Opus(クロード 3 オーパス)を発表し、大きな話題となった。その後、OpenAIが「GPT-4o」でトップの座を奪還したが、アンソロピックはさらなる一手「Claude 3.5 Sonnet(クロード 3.5 ソネット)」を発表して首位に返り咲いた。最新のベンチマーク「Hallucination Index」によれば、Claude3.5 Sonnet は比較対象となった22のLLMのうち、「最高のパフォーマンス」を示したという。日本でもようやく、Amazon Bedrockの1モデルとしてAWS東京リージョンでの提供が開始されたClaude3.5 Sonnetを、基礎からわかりやすく解説するとともに、さまざまなベンチマークテストでの実力を見ていきたい。
Claude 3.5 Sonnetとは何か?その実力とは
Claude 3.5 Sonnetとは、アンソロピックが2024年6月21日に発表したLLMの新モデルで、前バージョンのClaude 3 Opusと比較して、大幅な性能向上を実現しただけでなく、スピードが2~3倍、APIコストが5分の1に改善された。OpenAIが最近リリースしたGPT-4oをも超える性能を示しており、大規模言語モデル(LLM)開発競争で、また一歩リードした格好となる。
従来のClaude 3 Opusは、高い性能を持つものの、主要モデルの中ではスピードが最も遅く、またコストも群を抜いて高いことから、アプリケーションでの活用は難しいものがあった。
たとえば、1秒あたりの生成スピードを表すスループットは24トークンで、GPT-4 Turbo(28トークン)よりも遅かった。一方、コストはGPT-4よりも高く、100万トークンあたりのAPI利用料は、インプットで15ドル、アウトプットで75ドルに上った。これに対しGPT-4 Turboは、インプット10ドル、アウトプット30ドル。さらに最新モデルとなるGPT-4oは、スループットが約90トークンに改善し、コストもインプット5ドル、アウトプット15ドルまで下がった。
その点、Claude 3.5 Sonnetは、スループットが80トークンに上昇、コストはインプット3ドル、アウトプット15ドルと、GPT-4oに張り合うスピード/価格となっている。
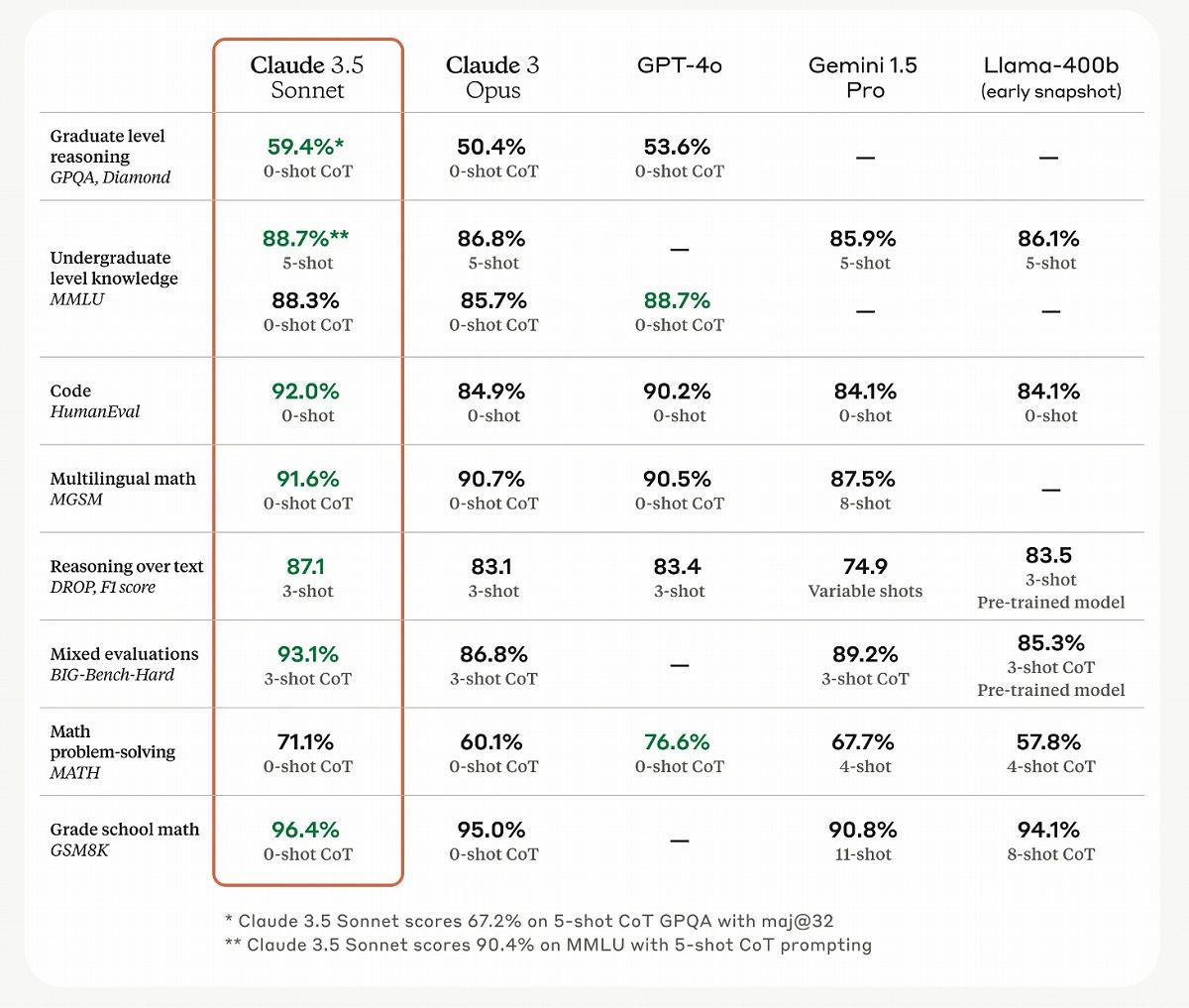
気になるアウトプットのクオリティだが、既存ベンチマークにおいては、主要モデルの中でトップの実力を示す。たとえば、大学院レベルの推論能力を測るGPQAでは59.4%を獲得。Claude 3 Opus(50.4%)、GPT-4o(53.6%)を超えた。
このほか、学部レベルの知識を測るMMLUで88.7%、コーディング能力を測るHumanEvalで92.0%のスコアを達成、MMLU88.7%、HumanEval90.2%を達成したGPT-4oに並ぶ性能を見せた。
(出典:アンソロピック)
特にコーディング能力の向上が顕著で、アンソロピックが独自に実施した評価テストによると、Claude 3.5 Sonnetはテスト問題の64%を解決、Claude 3 Opusの38%を大きく上回ったという。この評価テストは、オープンソースコードのバグ修正や関数追加などのタスクを行うもの。
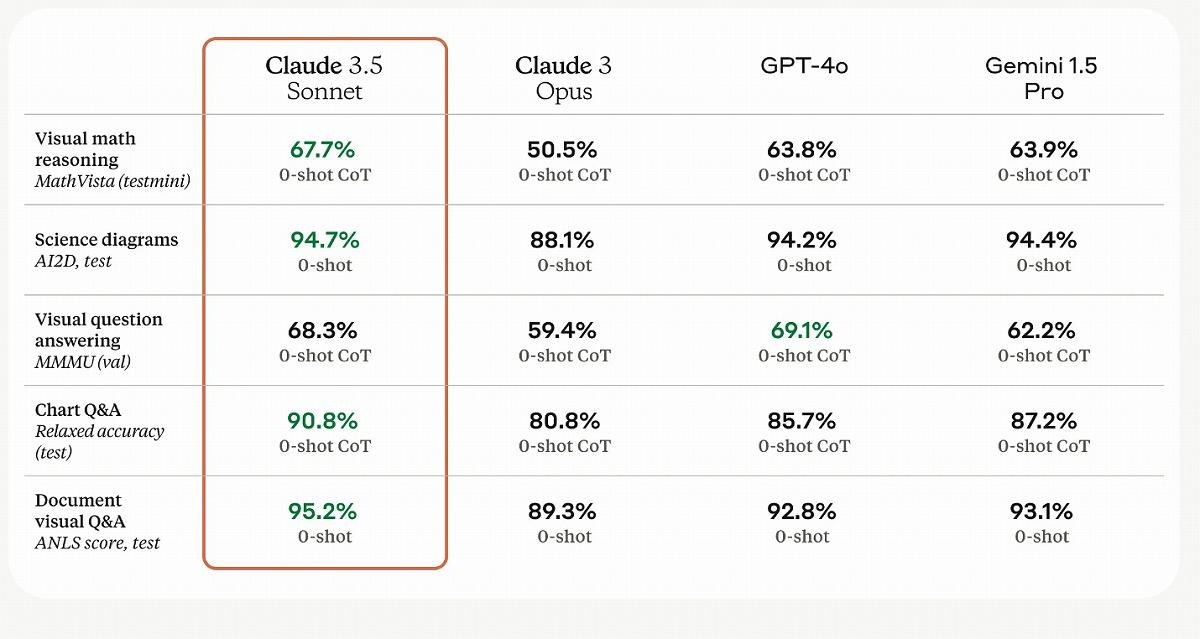
視覚的な処理能力も強化されており、各視覚ベンチマークでClaude 3 Opusを大きく上回った。特に、グラフや図表の解釈など、数学分野の視覚推論テストでは、Claude 3.5 Sonnetは67.7%とClaude 3 Opusの50.5%を20ポイント近く上回った。
(出典:アンソロピックのWebサイト)
新登場のベンチマークテストによる評価でも大躍進
AIコミュニティでは、トレーニングデータにテスト質問/回答が含まれる「データ汚染」問題により、既存ベンチマークではLLMの性能を正確に測ることが困難になっているという問題が共有されている。こうした中で新たに登場した「LiveBench」は、データ汚染問題を排除しつつ、LLMのパフォーマンスをより正確に測定できるとして注目されるベンチマークテストの1つだ。
LiveBenchの特徴は、arXiv論文、ニュース記事、IMDbの映画概要など新しいデータに基づいて質問を作成することで、潜在的なデータ汚染を制限するよう設計されている点にある。
さらに、各質問には検証可能な客観的な正解があり、エラーが多いとされるLLMの判断に頼らず難しい質問を正確かつ自動的に採点できるという利点がある。2024年7月時点では、6分野・17タスクが用意されており、今後より難しいタスクが追加される予定だ。
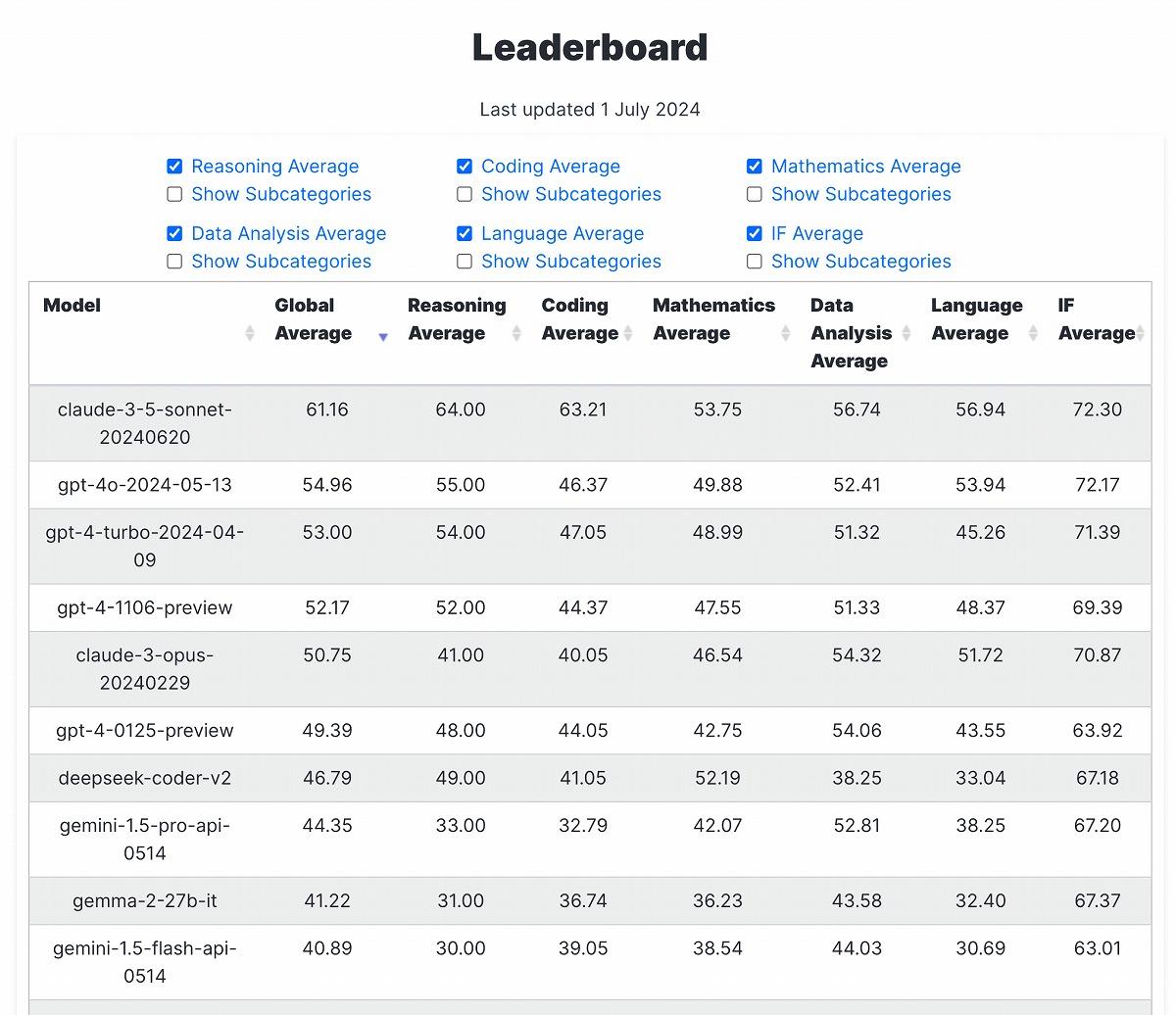
Claude 3.5 Sonnetは、このLiveBenchでも目を見張るパフォーマンスを示した。2024年7月1日時点のリーダーボードによると、総合平均スコアで61.16を記録し、2位のGPT-4o(54.96)を大きく引き離した。現時点で60以上のスコアを獲得したのはClaude 3.5 Sonnetのみだ。
カテゴリー別に見ても、Claude 3.5 Sonnetは「Reasoning(推論)」(64.00)、「Coding(コーディング)」(63.21)、「Mathematics(数学)」(53.75)、「Data Analysis(データ分析)」(56.74)、「Language(言語)」(56.94)、「Instruction Following(指示遂行)」(72.30)のすべてのカテゴリーでトップだった。
特に注目すべきは、コーディング能力を測る「Coding」カテゴリーでの成績だ。Claude 3.5 Sonnetは63.21のスコアを記録し、2位のGPT-4o(46.37)を16.84ポイントも上回っているのだ。これは上記アンソロピックの内部評価結果とも一致しており、Claude 3.5 Sonnetのコーディング能力が飛躍的に向上したことを裏付けるものとなる。
既存のコーディングテストであるHumanEvalでは、Claude 3.5 Sonnetが92%、GPT-4oが90%で接戦となっていたことを鑑みると興味深い結果といえるだろう。
(出典:LiveBench)
関連コンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
関連コンテンツ
あなたの投稿
PR
PR
PR
