- 会員限定
- 2024/06/22 掲載
Llama 3(ラマスリー)をやさしく解説、試してわかったメタのオープンソースLLMの弱点
メタが4月に発表したオープンソース大規模言語モデル(LLM)が「Llama 3(ラマスリー)」だ。80億と700億のパラメータを持つバージョンが公開され、いずれも他社モデルに匹敵する高いベンチマークスコアを記録する。特に80億モデルは同規模の他モデルを凌駕し、数学やコーディング能力の大幅改善を見せた。Llama 3を搭載した新チャットボット「Meta AI」のリリースにより、ChatGPTやClaude、HuggingChatへのキャッチアップを図る。本稿では、実際にいくつかのプロンプトで試して、その実力を試してみた。その結果見えてきた強みと弱みとは。
(出典:メタ)
Llama 3とは何か? その概要
「Llama 3」とは、メタが2023年2月に発表したオープンソースの大規模言語モデル「LLaMA」の最新版で、2024年4月に発表された。発表時点では80億(8B)パラメータと700億(70B)パラメータの2つのバージョンで構成され、現在4000億(400B)パラメータモデルも現在トレーニング中だという。
メタ幹部のラガバン・スリニバサン氏は4000億モデルについて「ベンチマークの観点からみると、本当に桁外れの性能を発揮している」とコメント。また同社AIチームのVP、マノハル・パルリ氏は「Llama 3の80億、700億モデルは、オープンモデルで最高の性能を発揮しており、一部のクローズドモデルにも匹敵、あるいはそれ以上だ」と豪語している。
メタのザッカーバーグ氏とネット上で一悶着あったイーロン・マスク氏も、Llama 3については「Not Bad(悪くない)」と評価するなど、おおむね好評価を得ている。
Llama 3はメタのチャットプラットフォーム「Meta AI」にも統合された。OpenAIのChatGPT、AnthropicのClaude、HuggingFaceのHuggingChatなど競合へのキャッチアップを目指す。Meta AIは、フェイスブックアカウントでのログインが必要だが、画像生成モデル「Meta Imagine」が使用可能となっている。ただし現時点ではマルチモーダル非対応で、画像やドキュメントのアップロードはできない。
(出典:メタ社)
なお、Llama 3はメタのオープンソースポリシーの下で公開されるが、ライセンス条件は一般的なオープンソースとは異なるため注意が必要だ(ソースは公開しているが、正確に言うとオープンソースソフトウェアではない)。
Llama 3のベンチマーク比較
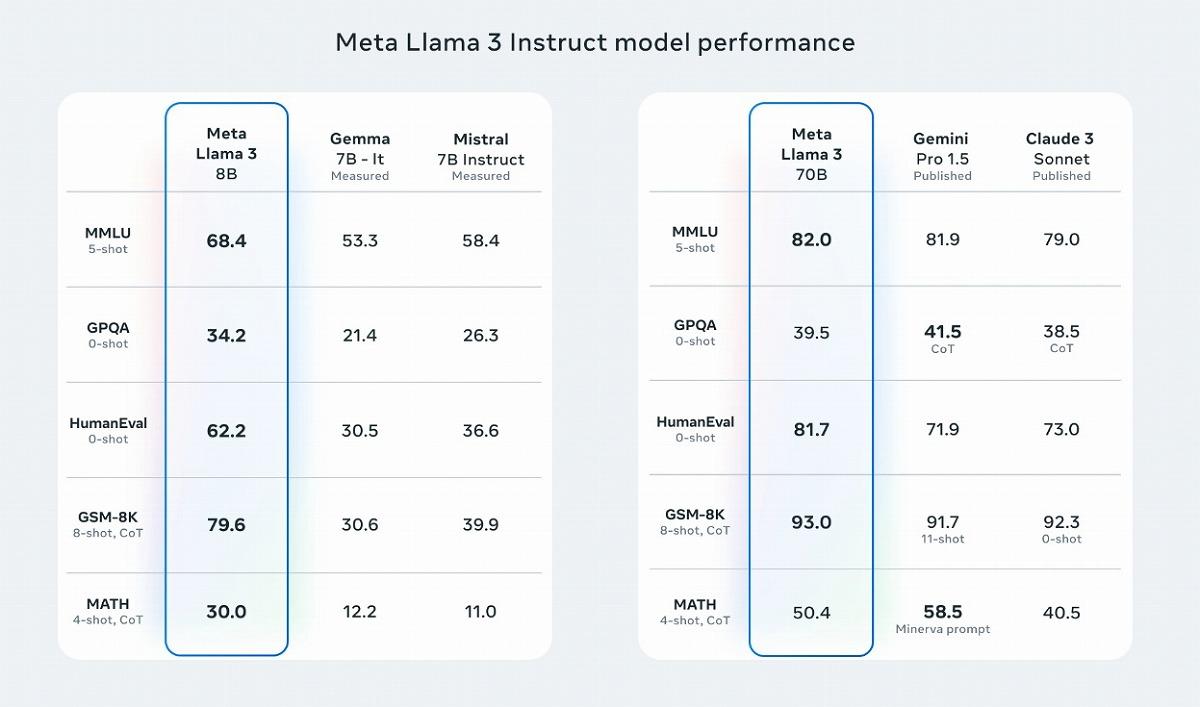
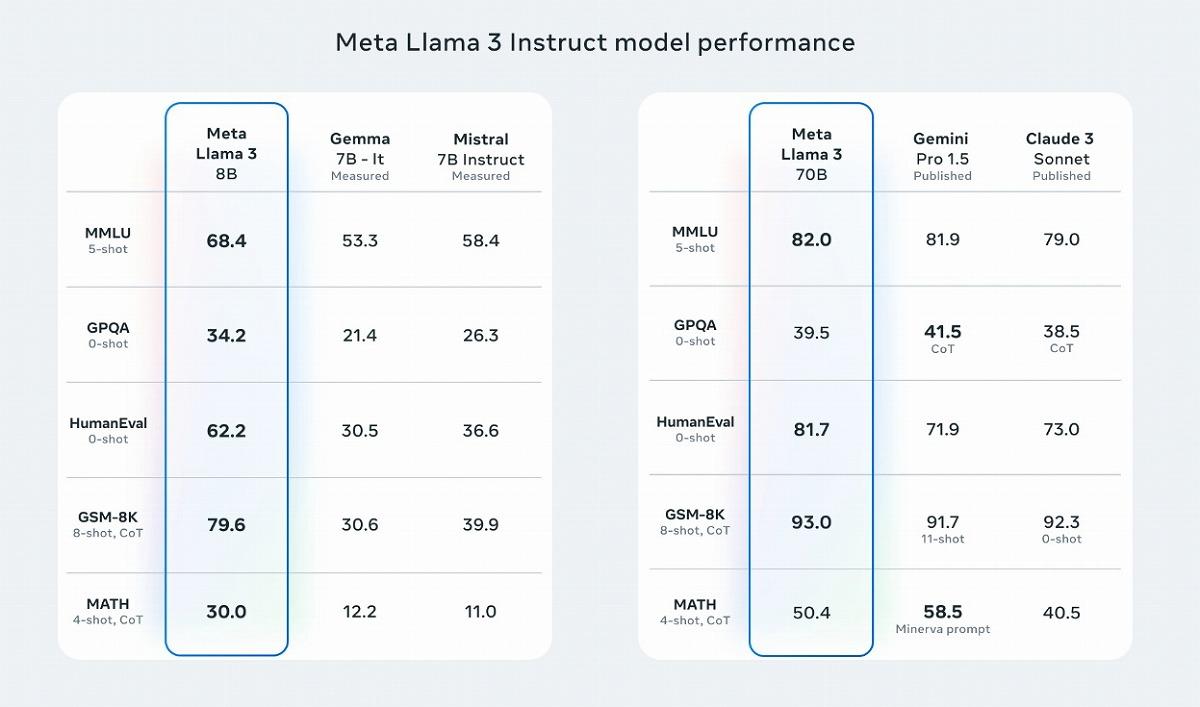
では、Llama 3はライバル各社のモデルと比べてどのような実力を持つのだろうか。ベンチマークスコアを比較してみたい。Llama 3の80億、700億モデルは、グーグルのGemmaやGemini Pro 1.5、AnthropicのClaude 3 Sonnet、MistralのInstruct 7Bなどのモデルと比べ、多くのベンチマークで同等の性能を示している。
(出典:メタ)
特に多肢選択問題(MMLU)とコーディング(HumanEval)で高得点を獲得した。一方で、700億モデルは、Gemini Pro 1.5には高度数学問題(MATH)と大学院レベルの多肢選択問題(GPQA)でやや及ばなかった。
対して80億モデルの健闘ぶりは目覚ましい。Gemma 7BやMistral 7B Instructをすべてのベンチマークで上回り、特に算数の文章問題(GSM-8K)で大きく引き離した。
700億、80億モデルともにみられるのは、コーディングにおける強みだろう。Pythonコーディングの生成能力を見るHumanEvalでは、700億モデルが81.7%を達成。これは、GPT-4の67%を大きく上回り、Claude 3 Opusの84.9%に迫る数値だ。GPT-4oは90.2%であり、これにはやや及ばないが、主要モデルの中でもトップクラスの水準にあるといってよいだろう。
80億モデルもパラメータ数が小さいながら、HumanEvalでは62.2%と、同規模のモデルの中では非常に高い数値を叩き出している。ちなみにGPT-3.5は48.1%と、80億モデルには遠く及ばない状況だ。 【次ページ】Llama 3の「特筆すべき」2つの強みと弱点
関連コンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
関連コンテンツ
あなたの投稿
PR
PR
PR
