- 会員限定
- 2022/12/01 掲載
「ベンダー丸投げ」をやめた東証、どうやって運用部門の地位を上げたのか
ソフトウェア品質シンポジウム2022(後編)
9月22日と23日の2日間、一般財団法人日本科学技術連盟主催のイベント「ソフトウェア品質シンポジウム2022」がオンラインで開催され、その特別講演として株式会社日本取引所グループ 専務執行役 横山隆介氏による「日本取引所グループシステム部門の取組み ~システムトラブルからの学びと今後の挑戦~」が行われました。
ITジャーナリスト/Publickeyブロガー。大学でUNIXを学び、株式会社アスキーに入社。データベースのテクニカルサポート、月刊アスキーNT編集部 副編集長などを経て1998年退社、フリーランスライターに。2000年、株式会社アットマーク・アイティ設立に参画、オンラインメディア部門の役員として2007年にIPOを実現、2008年に退社。再びフリーランスとして独立し、2009年にブログメディアPublickeyを開始。現在に至る。

現在、日本取引所グループ傘下の東京証券取引所(以下、東証)は、過去に何度か大きなシステムトラブルを経験し、それを教訓として組織とシステムの改善を続けています。
そこで今回、シンポジウム企画委員会からの要望を受けて行われた特別講演で、東証がこれまでのシステム障害から何を学び、そこから何を変化あるいは進化させてきたのか。わずか2年前のNASのハードウェア障害への振り返りも含めて語られます。
その上で、先進的な運用の取組みとされるSREに東証がなぜ挑戦しているのか、その理由と背景についても説明されました。
本記事はその講演の内容をダイジェストとしてまとめたものです。本記事は前編と後編で構成されています。いまお読みの記事は後編です。
ベンダー丸投げをやめ、サイロ化していた運用部門を統一
そこでようやくこのスライドの話に入っていけるわけなのですけれど、その2005年、2006年の東証にとって本当に歴史上非常にインパクトのある出来事があった。そして真摯に反省をした。そして、システム部門の整備に対して非常に大きな力を注いでいくことになります。
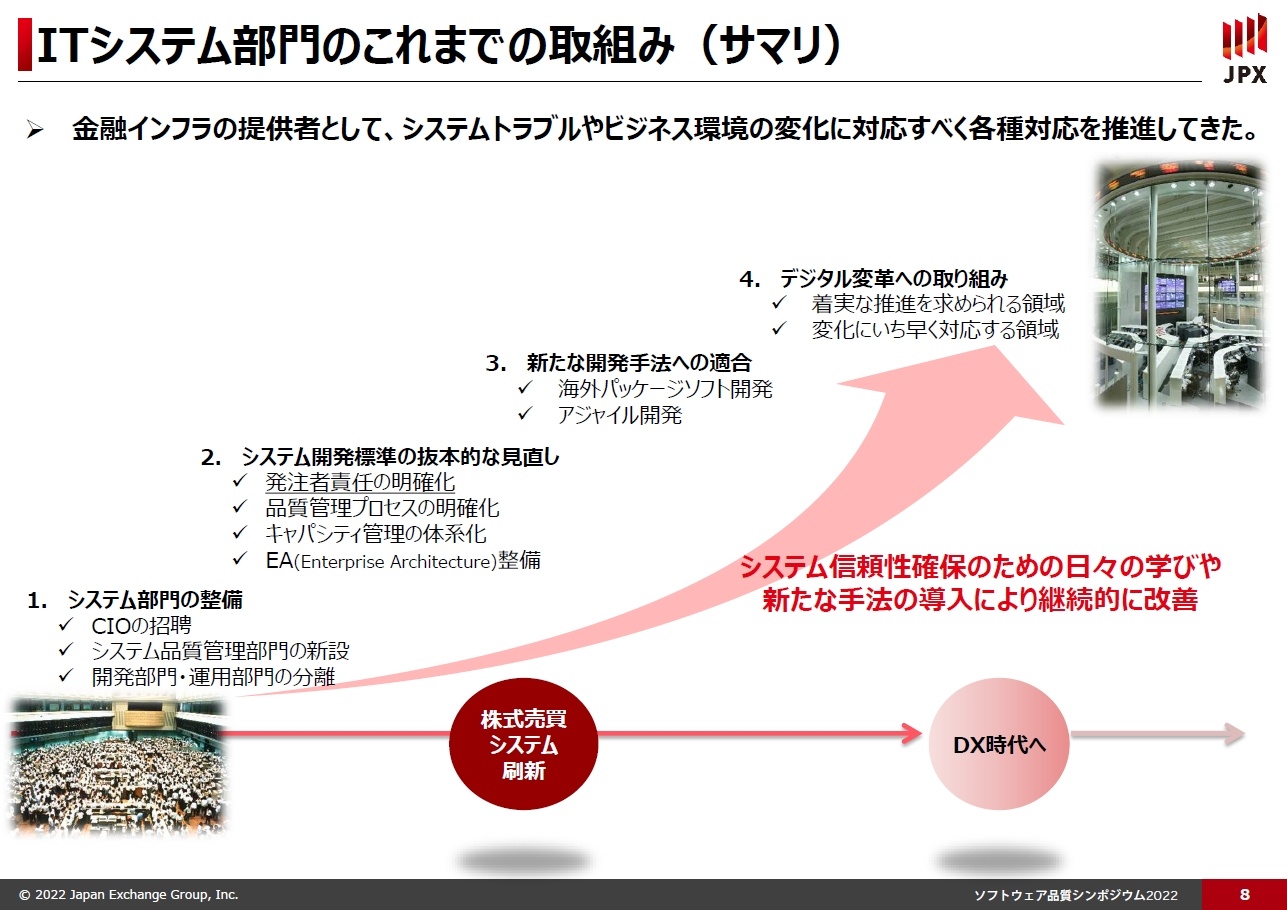
まず、CIOをというポジションを作るのですが、残念ながらCIOを担える経験、あるいはケイパビリティというのかもしれませんが、そうしたものを備えた人間が社内にはおらず、外部から招聘するということになりました。
そこでNTTデータにいらっしゃった鈴木さん(鈴木義伯氏)を初代のCIOとしてお招きし、強いリーダーシップや知見と、それからこれが非常に大事なのですが、当時のIT部門の頑張りが合わさって、その後のさまざまな施策を行っていくこととなります。
施策は様々ありますが、システムの開発全体のプロセスを抜本的に見直して、システムの品質を確保することに邁進していくことになります。
また、開発部門と運用部門を分離し、運用部門は完全に統合しました。
それまではベンダーに丸投げしつつ、ベンダーごと、例えば富士通や日立、NTTデータなどごとに縦割りになっていて開発と運用は分離されておらず、システム部門ごとに完全にサイロ化されていました。
そこを開発と運用を分離した上で、運用部門は全システムで統一した部署とし、当時の東証の標準的な運用スタイルに全部合わせました。
例えば売買システムの運用管理は富士通のSystemwalkerを使っていて、清算システムは日立のJP1を使っているところを、いろいろ抵抗があるなかで全部JP1に統一して可視化をする、といったことをしていたということです。
さらに、これはよくある話だとは思うのですが、部門が「業務」「システム開発」「システム運用」とあるとすると、業務部門が一番上で、システムの開発部門ではその下請けで、システムの運用部門はさらに開発の下請け、みたいな力(ちから)関係になりがちです。
そうなると業務部門は開発部門に対して要求を言いっぱなしで、開発部門はそれを聞いて作ったら、あとは運用部門に投げっぱなし、ということになってしまいます。
これでは、システムの安定運用をしようとしても絶対できません。だからこの力関係を逆にする、ということをずっとしてきました。
システム障害は運用しているときに発生します。ですから、システムを安定的に何年も運用するためには運用部門がとても大事になるのです。
発注者責任を明確化する
元CIOである鈴木さんが信念として強く言っていたのは「発注者責任を明確化する」ということです。発注者とは我々です。我々が、システムを開発する上での責任というものを明確化する。突き詰めるとそれは、ウォーターフォールの開発で言うと要件を我々がいかに明確に出せるかというところに尽きると思います。
以前は要件もベンダーに書いてもらっていたわけです。基本設計はおろか要件定義書から、もうベンダーに作成してもらっていた。
でも、それはもう全然駄目です。今でも我々がすべてを完全に作っている、というわけではありませんが、基本設計書も詳細設計書もシステム定義書も、それからテスト計画書も全部、我々がレビューしています。
そしてベンダーの工程に入ったとしても、そこでブラックボックスにせずに、途中の基本設計のプロセスでも詳細設計でも必ず品質評価をします。ベンダー内の単体テスト、システムテストも含めて全部結果を見て、ディスカッションもします。キャパシティ管理も相当体系化をして実施しています。
そうやって発注責任をきちっと明確化し、丸投げはしない。システム障害の責任は一義的にはベンダーでなくて我々です。我々の責任としてきちんと品質を高める必要があります。
一連の対応を頑張ってやり遂げて、その一つの成果として、初代のarrowheadが2010年に稼働しました。
2005年から2006年にかけて非常に深刻なシステム障害があり、初代のCIOが2006年に就任してから4年ぐらいかけて品質や運用の整備をし、それと並行して新しい売買システムをスクラッチから開発をして、2010年に稼働したわけです。
【次ページ】 運用部門の地位を向上させるための取組み
関連コンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
関連コンテンツ
あなたの投稿
PR
PR
PR
