- 会員限定
- 2011/07/14 掲載
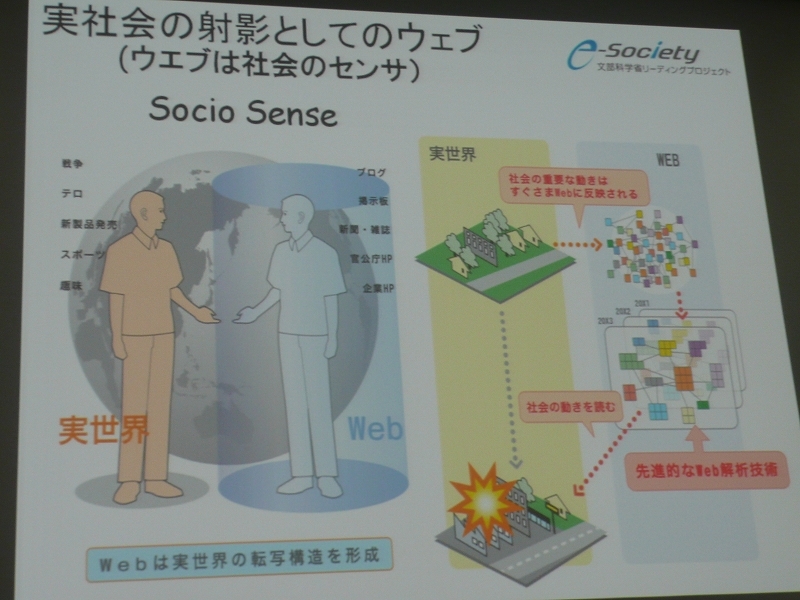
「非順序型データベースエンジン」による超巨大データベースから価値あるサービスを創出する
東京大学生産技術研究所 喜連川優教授
いまやサイバー空間には、咀嚼できないほどの情報が爆発的に増え続けている。その情報を超巨大なデータベースに蓄積し、いかに効率的に抽出し、解析することで、新しいサービスの創出につなげるか? この壮大なテーマに取り組んでいるのが東京大学生産技術研究所の喜連川優教授だ。喜連川教授は、最先端研究開発支援プログラム(FIRST)において、次世代の情報基盤を見据え、サイバーフィジカルサービス(CPS)のためのプラットフォームとデータベース・カーネルの研究、さらに新サービスの実証実験を推進している。ここでは東京大学 生産技術研究所および先端科学技術研究センターが主催した「駒場リサーチキャンパス公開2011」での喜連川教授の講演を紹介する。
震災に見る情報拡散~多様なメディアを駆使していく時代に

生産技術研究所
喜連川優 教授
では今回の3.11東日本大震災で情報メディアがどのように動いたのであろうか? 一口にネット上での情報メディアといっても、さまざまなツールがある。以前はブログが中心だったが、最近はツイッターが登場し、情報メディア自体の役割が変わってきた。そこでブログとツイッターの両者を使って、Web上に現れたキーワードの掛り受けを調べたという。
発災後は、両方とも「募金活動」というキーワードが多かった。ただしツイッターのほうが3月12日段階から募金活動という言葉が出始めるなど立ち上がりが早く、急激に広がった。ブログのほうはツイッターより立ち上がりは遅かったものの、ライフタイム(持続期間)が長いという現象がみられた。ツイッターは立ち上がりが早いが終息も早かったようだ。
またツイッターでの有用な情報の広がりを視覚化したツールも紹介。震災30分後には「風呂に水を貯めろ」「ガスの元栓を閉めろ」「ドアは開けておけ」など、阪神大震災の経験を踏まえたアドバイスが拡散された。その後、避難所の情報など、地震発生後3時間ぐらいまでに有用な情報が急激な勢いで広がっていった。普通の人が情報を発信し、それを見た有名人(インフルエンサー)が情報を拡散するというアプローチが見られたという。
たとえば節電の呼びかけや、停電に伴う情報収集、被災地への電力関係支援を行う「ヤシマ作戦」(TVアニメ・新世紀エヴァンゲリオンに登場する作戦名)は、当日のうちにツイッターで広がった。リアルタイム性ではツイッターが圧倒的に有利であり、ヤシマ作戦に見る草の根的な拡散パターンや、インフルエンサーによる拡散パターンなどについて、ネットで情報がどのように伝搬していくのか調査する術を持つことが重要になるという。喜連川教授は「最近のソリューションは5分単位で情報を取るようなリアルタイム性が求められているが、どのようなメディアが良いというのではなく、多様なメディアを駆使していく時代になっている」と指摘する。
| 
|
超巨大データベースの処理を超高速で実現する非順序型データベースエンジン
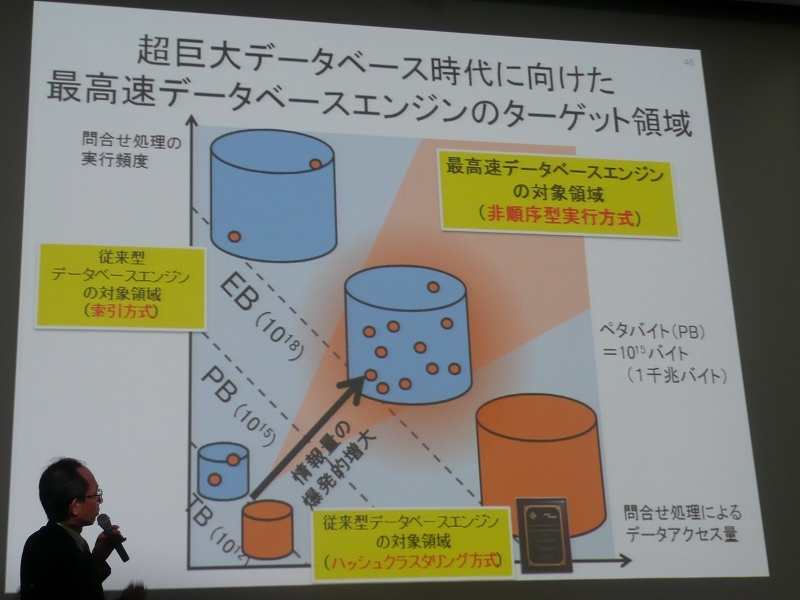
続いて喜連川教授は、主要研究である「超巨大データベース時代に向けた最高速データベースエンジンの開発と該当エンジンを核とする戦略的社会サービスの実証・評価」というプロジェクトについて解説した。これは、5年で世界のトップを目指す最先端研究開発支援プログラム(FIRST)に採択されたもの。端的に言うと「巨大なデータベースを支える超高速データベースエンジンをつくり、それを使って新しいサービスを提供することだ」という。現在のITの変化と問題点は、サイバー空間の情報が爆発するように増え続けていることだ。すでに咀嚼可能な限界をはるかに超えており、情報過多の時代に本当に必要な情報をいかに効率よく見つけられるかということが重要になっている。
「サイバー空間にあるデータ量の全体をざっくりと500エクサバイトとすると、485エクサバイトを占めるNon-Web情報のほうが重要」と喜連川教授は強調する。つまり、人が書いたり、つぶやく情報の量は大したボリュームではなく、センサーから発信されるような「モノがしゃべる情報」などのほうがはるかに多いのだ。
実際にWal-Mart Stores、Pacific Gas & ElectricなどのEコマース分野では「超巨大データベース」ができており、その情報のほとんどがRFIDや電子タグのようなセンサーから得られる情報だ。
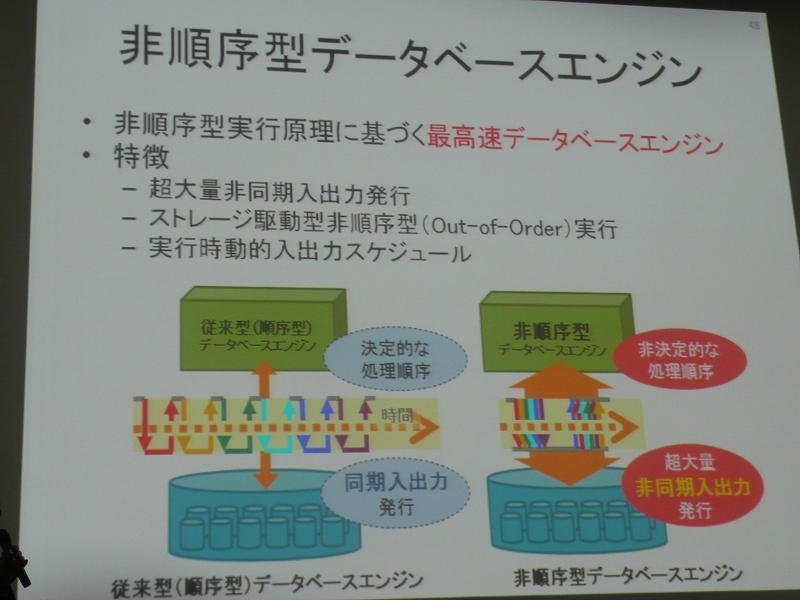
しかし、このような超巨大データベースでの問い合わせ処理は、従来型データベースエンジンのような「インデックス方式」や「ハッシュクラスタリング方式」ではなく、新しい方式が必要だという。前者は銀行ATMのように少量データで何度も問い合わせをするケース、後者はBIのような解析において大量データを処理するケースなどに用いられてきた。実はこの20年以上、RDBエンジンのアーキテクチャには変革は起きていない。喜連川教授が研究しているのは両者の中間に位置するもので、「非順序型実行原理」という新しい理論に基づき、従来と比べて圧倒的に速い「非順序型データベースエンジン」を開発しているところだ。
従来型のデータベースエンジンでは同期I/Oによってデータの問い合わせと結果が順番に繰り返されるが、この非順序型データベースエンジンでは非同期I/Oによって結果が返ってくる前に、どんどん問い合わせをする。結果も問い合わせをした順番とは関係なく返ってくる「非決定的な処理順序」が大きな特徴だ。非同期では、とにかく処理できるところから実行するという手法である。喜連川教授は、実システムや実証環境、ベンチマーク結果などについても紹介した。エンジンは日立製作所のHiRDBをベースに開発しているという。ハードウェアを変えずに、ソフトウェアだけを変えるだけでベンチマークの結果は100倍以上も向上したそうだ。

| 
|
| 
|
【次ページ】サイバーフィジカルサービスとは? 超巨大データベースからの価値創出
関連コンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
あなたの投稿
PR
PR
PR
