- 2011/03/08 掲載
富士通、重複顧客データの高速名寄せ技術を開発 従来の10倍に
富士通研究所は8日、顧客データベースの中から同一の顧客を示すデータを高速に検出する技術を開発したと発表した。顧客データの名寄せに特化した類似検索手法を用いることにより、従来と同等の精度を保ったまま、処理速度を従来の約10倍に高速化したという。
顧客データベースの名寄せでは、顧客の名称や住所、電話番号といった顧客を特定できる項目の類似性を調べて、多くの項目で一致または類似した値をとるデータの組を同一顧客と判定する。しかし、大規模な顧客データベースにおいて、すべてのデータの組み合わせについて項目ごとの類似性を計算するのは処理に時間がかかる。
そのため、顧客データベース中の郵便番号などの特定の項目を用いて、データをいくつかのグループに分割しておき、分割したグループに属するものどうしで類似性を判断することで処理速度を向上させる方法が使われていた。
しかし、この方法では郵便番号などが同じグループ内にあるデータの組しかデータの類似性を判断できないため、グループを小さく分割した場合には名寄せしなければいけないデータの見落としが発生し、逆にグループを大きく分割すると処理に時間がかかるという問題があるという。
今回開発した技術では、顧客データベース中のデータを、従来のように郵便番号といった一つの項目だけを対象に分割するのではなく、すべての項目内容を対象に他の顧客データの中から類似するデータを検索し、各項目の検索結果を総合評価することで、名寄せの見落としを少なくした。
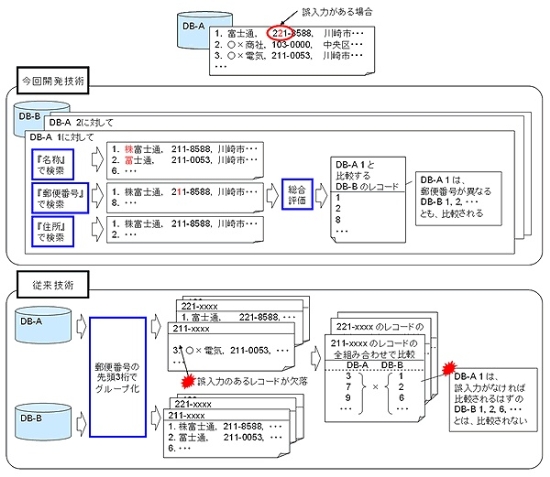
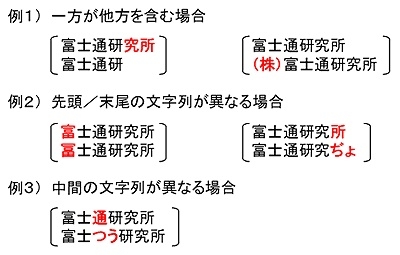
さらにデータどうしに共通部分があり、文字の先頭や末尾、あるいは中間部分の一箇所のみが違う程度のものであれば類似であると限定したうえで、データを高速に検索できる手法を用い、名寄せ精度を保ちつつ処理速度を向上させた。
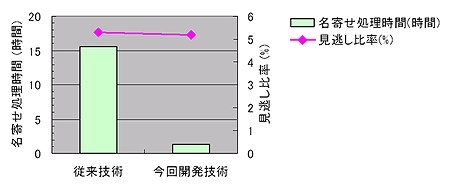
今回開発した技術を10項目からなる約200万件の顧客情報に名寄せを適用した場合、従来技術では名寄せ処理に15.5時間かかったが、今回開発した技術は、同等の名寄せの見逃し比率を保ちながら、1.4時間と従来技術の約10分の1の時間で名寄せ処理を終えることができたという。
富士通研究所では、2011年度中に今回開発した技術を用いた顧客名名寄せの実用化を目指し、企業合併やITシステム統合の際に必要となるデータベース統合を支援していく。また、顧客データ以外のテキストや画像・動画のタグなどに対象範囲を広げてデータを統合する研究開発を進め、さまざまな情報を連携させたサービスの提供につなげていくという。
共有する
-
0
-
0
-
0
-
0
-
0
-
0
関連コンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
関連コンテンツ
あなたの投稿
PR
PR
PR
