- 会員限定
- 2024/05/22 掲載
GPT-4oをわかりやすく解説、専門家が「時代の転換点」と評価するヤバすぎる能力とは
2024年5月、OpenAIは突如として最新のAIモデル「GPT-4o」を発表しました。末尾のoは「omni」の略称で、その意味は言語、画像、音声、動画を1つのモデルで処理できる能力があること。この能力を活用したリアルタイムのデモは、全世界の専門家に衝撃を与えるものになりました。このGPT-4oについて、『生成AIで世界はこう変わる』の著者で、元東大 松尾研究室の今井翔太氏は「時代の転換点になった」とまで評価しています。ここでは、GPT-4oは何が凄いのか、過去のモデルと何が違うのか、わかりやすく解説します。
(出典:OpenAI)
突然の発表になった「GPT-4o」前夜
それに先立ち、4月の後半からは、生成AIの性能を比較するサイトで、正体不明のモデル「gpt2-chatbot」なるものが出現し、制作者が不明である中、当時最高の性能を誇っていたGPT-4を上回る性能を見せつけていました(もちろんOpenAIはすでに「GPT-2」を数年前に発表済みです)。では今更このような名前をつけて暴れ回っているこれは何なのか。OpenAI製なのか、それとも別の機関が開発したのか。
この話は後々答えがわかるのですが、このようにAI研究者たちが落ち着かず、あれこれと噂してOpenAIの動向に注意している中、OpenAIは日本時間の5月11日、わずか3日後の5月14日にライブ配信を行い、ChatGPT/GPT-4のアップデートを発表すると、Xで告知を行いました。
ライブの正確な日時は日本時間で5月14日の午前2時。ちょうど24時間後の5月15日の午前2時には1年に1度行われるグーグル最大のイベントGoogle I/Oがあり、明らかに意図的なグーグルへの挑戦を意識した日程です。
このライブの中でOpenAIは、最新の生成AI/大規模言語モデル「GPT-4o(ジーピーティーフォーオー)」を発表しました。
OpenAIによると、oは“omni”を略したものであるそうです。「omni」は日本語で「すべての…、全…」などを意味します。OpenAIが命名意図を公開していないため、これは推測ですが、おそらく「言葉、画像、音声、動画の“すべて”を処理できるようになったGPT」といったような主張が背後にあるものと考えられます。
このライブは26分と非常に短いものでしたが、ここで行われたGPT-4oのデモは世界中に衝撃を与えました。

(出典:OpenAI)
全人類が史上最高のAIを使えるようになった「時代の転換点」
ライブの内容は、スマホ上で動作するGPT-4oを相手に、スマホのカメラで外の様子を撮影しつつ、声によって会話を行うというものでした。何気ない日常的な会話、数学の問題を一緒にやる、プログラミングを一緒にやる、図を理解させる、複数言語間の翻訳を行う、などといった非常に幅広い内容のやり取りです。ただ「人間とAIが対話を行う」ということであれば、アップルのSiriやAmazon Alexaなどのスマートスピーカーや今までの生成AIアプリでも可能でした。しかし、今回のデモで発表されたGPT-4oは、カメラで撮影されている人間の表情、背景、紙に描かれていることなどをリアルタイムで間違いなく認識し、応答までのスピードもまったく人間と変わらないという驚異的なものでした。
さらにこのやり取りの中でGPT-4oは、笑い、言いよどみ、驚き、歌うなど、人間のような感情表現を見せ、従来のAIのような機械的な応答とはかけ離れた振る舞いを見せました。
たとえば、OpenAIのライブにおいて「I♡ChatGPT」と書かれた紙を見せられたGPT-4oは、感極まった声の調子で息遣いすら感じる笑いとともに人間に対して応答しています(発表時の動画の17分20秒付近)。
ここまでくると、単に会話の音声だけを聴いて、これが人間同士ではなく「AIと人間の会話」だと認識できる人はほぼいないというレベルです。SF世界のAIが現実世界に出てきてしまいました。
そして、ここで公開されたGPT-4oは、ライブの終了後、ChatGPTの無料ユーザーも含め、すべてのユーザーに対して利用可能になりました。全人類が史上最高のAIを使えるようになった、時代の転換点です。
GPT-4oとはそもそも何か? 技術情報を解説
ここからは、今回のOpenAIが発表したGPT-4oについて重要な点、技術情報をわかりやすく解説します。まず、GPT-4oは言語や画像、音声、動画のすべてを処理できるマルチモーダルモデルです。マルチモーダルというと少し聞きなれない言葉かもしれませんが、要するに、言語や音声、画像などさまざまな情報=モダリティをまとめて処理できるAIであるということです。
今までのChatGPT/GPT-4でも部分的なマルチモーダル機能は実現されていましたが、GPT-4oではさらにこれが強化されています。GPT-4oは単一のニューラルネットワークで、言語、画像、音声、動画を入力でき、また出力もできるようになっています。入力できるトークンの上限は12万8000トークンになっています(GPT-4 Turboと同等、GPT-4は3万2768トークン)。
言語/テキストの入出力性能については、以前からChatGPTを使っていたユーザーであればご存じのとおりです。研究者やコアユーザーたちは先ほど触れたgpt2-chatbotというGPT-4oの事前公開版を使ってその性能を実感していますし、GPT-4o公開後は無料ユーザーにも開放された圧倒的な性能に関する報告がSNSでいくつもあがっています。
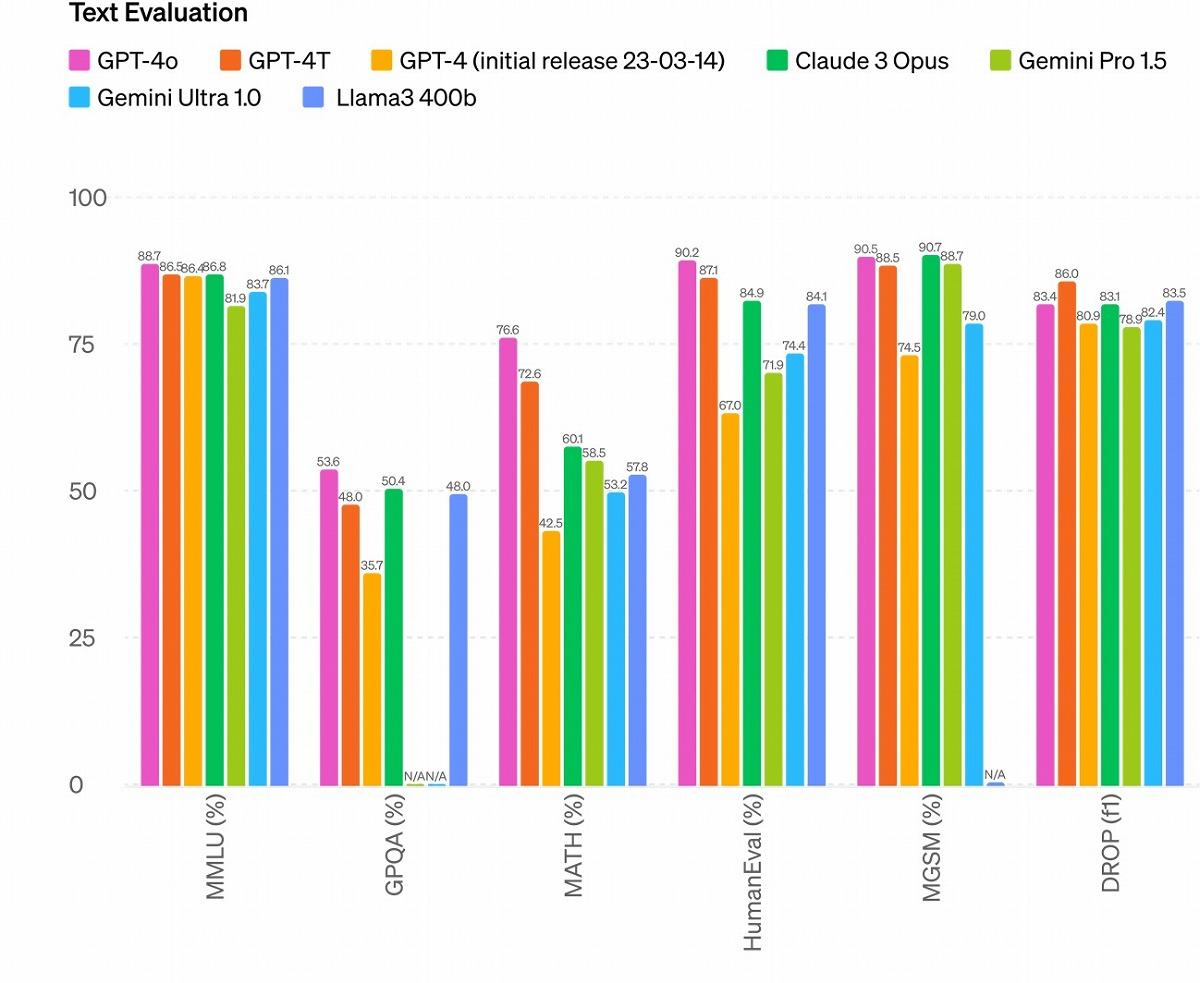
以下は、OpenAIの公式ページで報告されている、GPT-4oと今までの最高性能の言語生成AIモデルを比較した図です。
(出典:OpenAI)
ここでは言語性能を測る主要なベンチマーク(AIに対して、義務教育レベルの文章問題やプログラミングのテスト)で各モデルを比較しています。
一応、GPT-4以外の各モデルについて解説すると、Claude 3 Opusはアンソロピックが開発した、「はじめてGPT-4を超えた」と有名になったモデル、Geminiはグーグルが開発したGPT-4oと同じマルチモーダルモデル、Llama3はメタが開発したオープンモデル(誰でもモデルの本体をダウンロードし、カスタマイズするなどして使える)の最高峰です。
さらに補足として研究者視点でいうと、我々はだいたいMMLU(Massive Multi-task Language Understanding)というベンチマークのスコアを真っ先に見ます。これは数学、哲学、法律など、さまざまな学問分野に関する選択式問題の結果です。
このベンチマークでGPT-4oは最高性能を叩き出しており、その言語性能の凄まじさは、ユーザーの感覚だけでなく、定量的な評価からも明らかです。 【次ページ】音声や動画像を理解できる「最大のメリット」とは?
関連コンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
関連コンテンツ
あなたの投稿
PR
PR
PR
