- 会員限定
- 2021/07/29 掲載
【AWS直伝】スタートアップ拡大期に使うべきAWSサービスまとめ、運用やデータ活用は?
連載:スタートアップのためのAWS活用入門
リソースの限られたスタートアップでクラウドサービス、特にAWS(Amazon Web Services)をどう活用すべきか紹介する本連載。第1回は、シード/アーリーステージのスタートアップにおけるシステム面の検討事項として、主にMVP構築〜PMF達成前後に直面するよくある技術課題と、それに対処するためのAWSの活用方法を紹介した。今回はその続きとして、さらにステージが進んだミドル/レイターステージに起こる課題について、実際にスタートアップ企業から受けてきた相談などをもとに、AWSの塚田 朗弘氏がまとめた。
2011年から生放送系ウェブサービスの開発を経験した後、2013年よりスタートアップ企業にJoin。CTOとしてモバイルアプリ、サーバサイド、AWS上のインフラ管理を担当しつつ、採用やチームマネジメントを行う。2015年8月よりアマゾンウェブサービスジャパン株式会社のソリューションアーキテクトとして、主にスタートアップ領域のお客さまに対する技術支援を担当。技術的な得意/興味領域としては、設計原則に則ったプログラミング、ブロックチェーン、サーバレス・モバイル系テクノロジーなど。

(Photo/Getty Images)
運用/データの活用/セキュリティとコンプライアンスが課題に
スタートアップに一番大切なものの1つはスピードだ、ということは前回に続き変わらない。シリーズB、Cとラウンドを重ねていくにあたって資金は増えてくるかもしれないが、一銭たりとも無駄にできる金がないのは依然変わらないのである。また、開発チームのみならず会社の組織全体が徐々に大きくなってくるにつれて、必然的にシステム的にもアーキテクチャやアプリケーションの最適化をしなければスピード自体が確保できなくなってくる。システムは、そのときそのときの最良の(と思われる)判断に基づいて構築され歴史を紡ぐが、時間が経てば要件なり技術要素なりの変化に伴って最適解も変わるものだからである。
かといって最適化やリファクタリングのタスクを優先すればよいのか、いや機能開発タスクも捨て置けない、さてどちらを優先するべきか……といった具合に、誰にも簡単に判断できないような問題が出てくる。これらはビジネス上の戦略なくしては判断できない検討事項なのだが、このときエンジニアチームとビジネスサイドのメンバーが分断されているがために開発チームがいわば「社内受託」のような状態になってしまっていることもしばしばある。
この記事を読みながら、それぞれの項目についてぜひ「いつこれを手掛けるべきか」を考えてみていただきたい。前回の記事でも述べたが、PMFを達成しグロースフェーズに入ったとき、一般的にはビジネスの急成長やステークホルダー(株主等)の増加に伴って機能拡張等の要求も強まり、既存のシステム課題(しかし直さなくても仕様通り動作はする類の課題…)を解決するタスクと混ざって優先順位付けが複雑になってくるからである。
では、スタートアップにおけるシステム面での問いを考えていこう。前回も書いたが、PMF以降、急増するユーザー等に対応するためのスケーラビリティや信頼性が非常に重要になる。今回はさらに、運用の最適化、データの活用、セキュリティとコンプライアンスといったよくある課題を取り上げた。
運用に関する課題
筆者がこれまで頻繁に相談を受け、対応してきた内容の1つがシステムの運用効率化についてである。理想的にはPSF(Problem/Solution Fit)後には、そしてできればPMF前には構築、運用を自動化できていれば結果的に開発スピードも高く保てるのだが、みんながそんな簡単に実行できればソリューションアーキテクトは要らず、筆者は廃業する(個人的にはそういう未来があるべきだとは思う)。「早すぎる最適化」との見分け方も難しい。まず、手作業による運用は極力排除しておかなければいけない。このステージでは、後述するように人員採用も活発になってくることが多い。ただでさえ機能追加開発が忙しい中で、新しく10人、20人、50人……と入ってくるエンジニアが一日も早く開発要員として活躍できるようにしなければならない。1人の中途採用エンジニアが入社して、1人分の戦力として活動できるまでに御社ではどのくらいの時間を必要としているだろうか?半日で済むのか1週間かかるのかで全体のスピードは大きく異なってくる。
では、実際によくある相談をベースにいくつか自動化のポイントを見ていこう。
問1.デプロイの自動化をどうすべきか?
ミドルステージのスタートアップ企業からは、「まだちゃんとデプロイパイプラインを作りきれていない」という相談もしばしば受ける。デプロイが自動化できていないことによってさまざまなデメリットが考えられる。
- デプロイ頻度の低下。デプロイ頻度はしばしば DDD (Deploys / Developer / Day) などで計測され、生産性や開発速度に類する指標として使われる。
- デプロイ作業時の人為的ミスの可能性。デプロイは一般的に本番環境に変更を加え得るものであり、ミスの影響は大きい恐れがある。
- デプロイ作業人員の属人化。「デプロイ係」のような人ができてしまい、増加する新メンバーがデプロイしたくてもできず、ボトルネックが生じる。
では自動化しようと思ったときに使えるAWSのサービスには、たとえば次のようなものがある。
- AWS Cloud Development Kit (CDK)
AWS CDKは、TypeScript、Python、Javaなど使い慣れたプログラミング言語で、安全にAWS上のリソースを定義、プロビジョニングできる、いわゆるInfrastructure as Codeを実現できるフレームワークである。CDK for Terraformを使ってTerraformと、cdk8sを使ってKubernetesと組み合わせて使うこともできる。AWSの構成自体をコード管理し、自動化するのに有効なツールだ。
- AWS CodePipeline
CodePipelineはフルマネージドの継続的デリバリーサービスだ。デプロイパイプラインを定義し、たとえばGitHubなどのソースコードリポジトリと連携し、pushやmerge操作などコードの変更をトリガーにして実行することができる。AWS IAMによる権限を伴った承認アクションなども挟むことができる。
- AWS CodeBuild
CodeBuildは、ソースコードのコンパイル、テスト、コンテナイメージのビルドなどを実行できるフルマネージドビルドサービスだ。YAML形式で実行するコマンドを記述することができ、複数のビルドが同時実行されるため待たされることがないのも特徴。1つ前で挙げたCodePipelineで定義するパイプライン内のアクションとしてCodeBuildを呼び出し、ビルド、テスト等を実行することも多い。
- AWS CodeDeploy
CodeDeployは、Amazon EC2、AWS Fargate、AWS Lambda、オンプレミスで実行されるサーバなど、さまざまなコンピューティングサービスへのソフトウェアのデプロイを自動化する、フルマネージドのデプロイサービスだ。Blue/Greenデプロイメントや、本番反映前のテスト機能などを提供する。
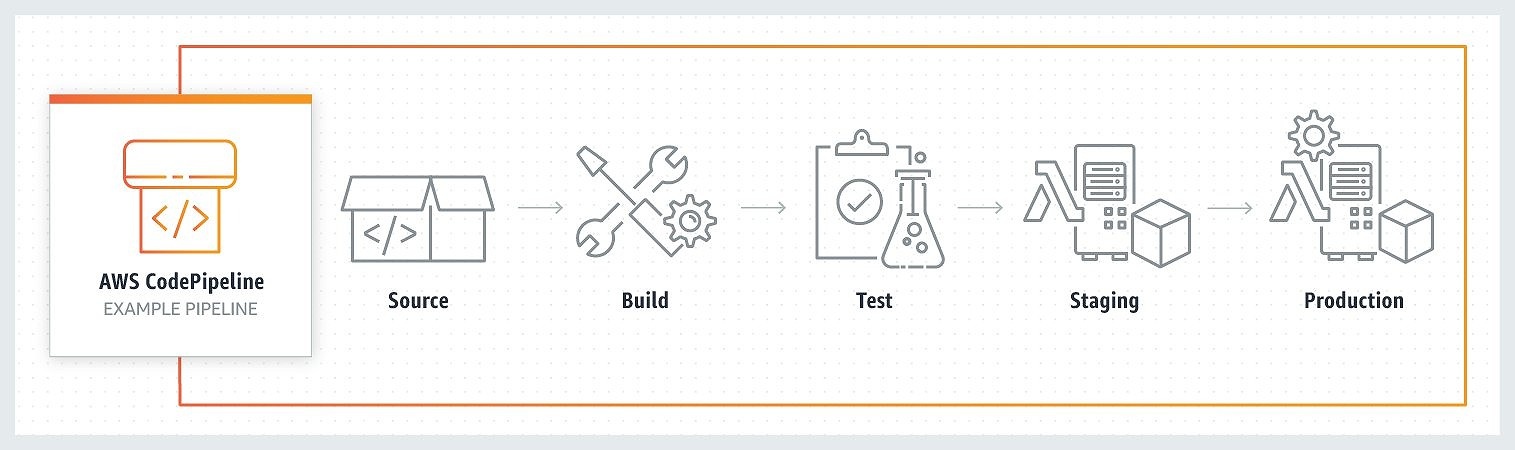
(出典: AWS CodePipeline)
フェーズが進むにしたがって、SREの原則で言うところの「トイル(本来は自動化可能な、労苦)」の影響は大きくなりがちである。これらのパイプラインを早めに整備しておきたい。
問2.監視と通知、障害対応の自動化をどうすべきか?
システムは、不具合や障害が必ず発生することを前提にアーキテクチャを設計し、運用することが重要だ(この考え方はDesign for Failureと呼ばれる)。
スタートアップ企業の方によく案内する内容を大きく分けると、「異常を検知できるよう監視すること」 「異常を検知したときに通知すること」 「検知・通知を受けて対応すること」となる。それぞれ見ていこう。
1.異常を検知できるよう監視する
Amazon CloudWatchは、各種のAWSサービスに統合されたモニタリング・オブザーバビリティサービスだ。たとえばAmazon EC2のインスタンスを起動すると、CPU利用率などのメトリクスが確認できるのはCloudWatchの機能である。また、CloudWatch Logsを使うと任意のログを収集することもできる。CloudWatchにアラームの条件を定義しておき、これらのメトリクスやログに条件を満たす情報が現れたとき検知することができる。
ここでしばしば、「どんな項目を監視すればよいのか」と相談を受けることがある。最終的にはシステム要件次第になるのだが、「どのメトリクスがどうなっているときに、ユーザーおよびサービスにはどういう影響が出ていて、どう検知されるべきか」を考えて設定することが重要だ。たとえばElastic Load Balancingのメトリクスで `HTTPCode_Target_5XX_Count` の数を条件に設定すれば、ロードバランサーの後のサーバプロセスが500系エラーを返しているときに検知することができる。
2.異常を検知したときに通知する
CloudWatchでアラームを設定したら、その発生時にどのような通知を出すかを併せて定義することができる。Amazon Simple Notification Service (SNS) はフルマネージドのpub/sub型メッセージングサービスであり、定義したトピックをCloudWatchアラームの通知先として選択できるようになっている。
3.検知・通知を受けて対応する
CloudWatchのアラームからAmazon SNSのトピックにメッセージを飛ばせば、後は該当トピックにサブスクライブしている先ごとに柔軟に対応を実装できる。たとえば、Amazon Chatbotに連携すればSlackやAmazon Chimeにアラーム内容を送信し、人に知らせることができる。
シンプルにSNSトピックにシステム管理者等のEメールアドレスをサブスクライブしておけば、メールで通知することも可能だ。または、AWS LambdaやAWS Step Functionで対応内容自体をワークフローやプログラムとして実装してしまい、アラーム発生時に任意の処理を自動で実行させるといったこともできる。
また、前回の記事で書いたAWS Auto ScalingもCloudWatchのアラームをトリガーにスケールアウト・スケールインさせることもでき、たとえばWebページへのアクセスが増えてきてサーバ負荷が上がってきたときに自動でサーバを追加する、といったアクションも、「検知・通知を受けて対応する」例といえる。
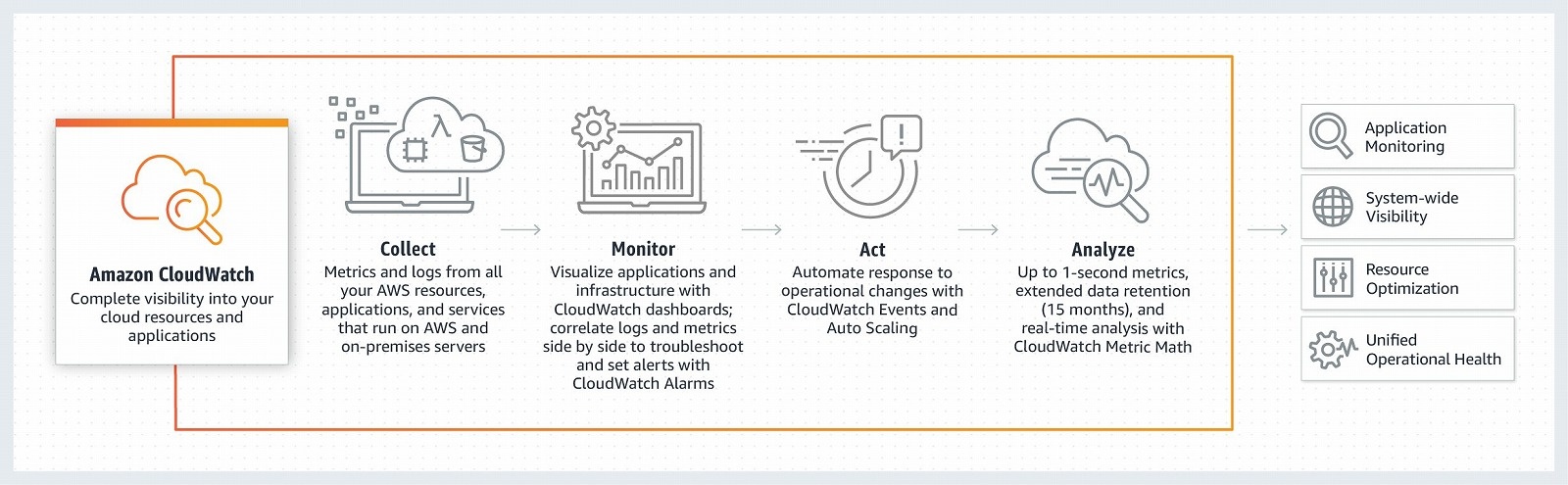
(出典: Amazon CloudWatch)
ここで書いたのはAmazon CloudWatchを中心とした基本的な例だが、汎用的に使える考え方であり、システムの各所で考慮できているかをチェックしてほしい。
【次ページ】データ活用、セキュリティとコンプライアンスに関する課題
関連コンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
関連コンテンツ
あなたの投稿
PR
PR
PR
