- 会員限定
- 2024/11/25 掲載
OpenAI o1(ChatGPT o1)とは何かをやさしく解説、従来と何が違う? 特徴や使い方とは
OpenAIの最新AIモデル「o1(オーワン)」は「推論トークン」という新しい仕組みを活用した、従来のGPTとは一線を画す言語モデルだ。特にコーディングや数学で高い精度を実現し、あるベンチマークテストでは博士課程の学生を上回る成績を記録したとされる。この最新モデルo1とは、どのような特徴を持つモデルなのか、どんな場面で利用すると有効なのか、その実力や使い方をわかりやすく解説する。
英大学院修了後、RPA企業に勤務。大手通信社シンガポール支局で経済・テクノロジーの取材・執筆を担当。その後、Livit Singaporeでクライアント企業のメディア戦略とコンテンツ制作を支援(主にドローン/AI領域)。2026年2月、シンガポールで「SimplyPNG」を設立し、AI画像編集のモデル運用とGPUコスト最適化を手がける。主にEC向け画像処理ワークフローの設計・運用自動化に注力。
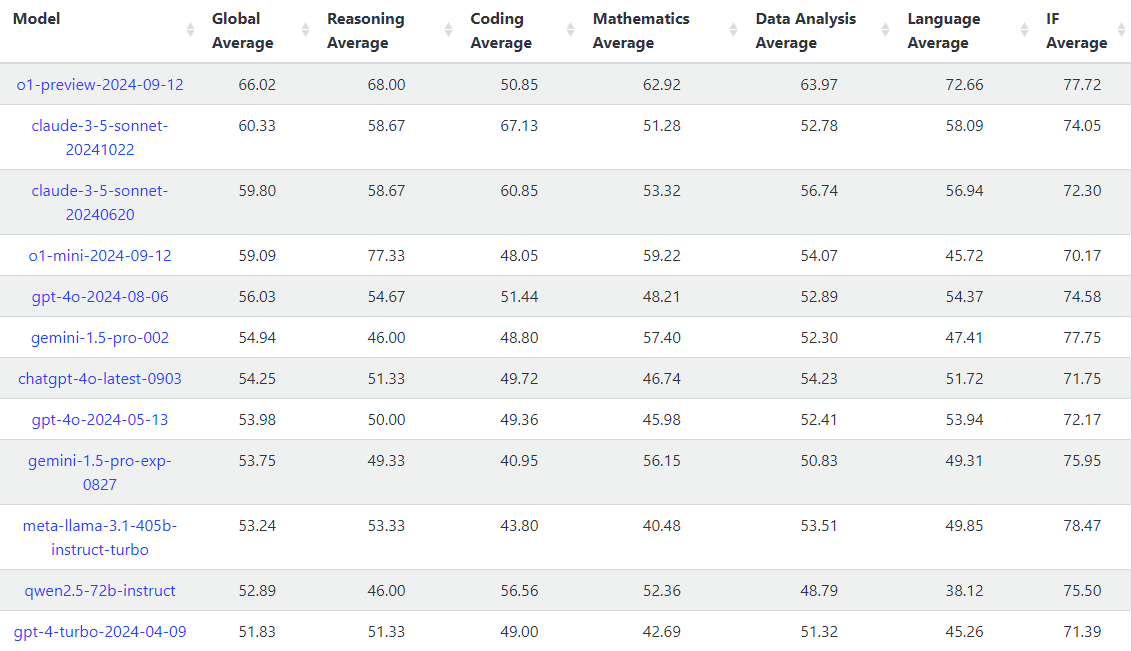
(出典:LiveBench)
o1とは?「o1-preview」と「o1-mini」の違い
o1モデルの最大の特徴は、その高い推論能力にある。OpenAIによると、o1-previewは競技プログラミングの問題(Codeforces)で89パーセンタイルにランクされ、米国数学オリンピック予選(AIME)では83%のスコアを獲得(以前は13%)して上位500人の学生に匹敵する成績を収めたという。さらに、物理学、生物学、化学の難しい問題に関するベンチマーク(GPQA)では、PhD(博士課程)の学生を上回る精度を示したとされる。

(Photo:Mojahid Mottakin / Shutterstock.com)
一方、o1-miniはo1シリーズの高度な推論能力を保持しつつ、o1-previewの約3倍の回答速度、80%ほど低コストなモデルとして設計されており、コーディングや数学、科学タスクに特化。幅広い一般知識(extensive general knowledge)を必要としない場面での使用に適しているという。
o1モデルとGPTモデルの大きな違いは、o1モデルが「推論トークン」と呼ばれる新しい手法を採用している点にある。モデルはこれらのトークンを使用して「思考」し、プロンプトの理解を深め、複数のアプローチを検討した上で応答を生成するという。推論トークンは生成後に破棄され、コンテキストには保持されない仕組みとなっている。
o1の卓越した性能
OpenAIの新モデル「o1」は、サードパーティーによる各種ベンチマークテストにおいても、その卓越した性能を見せつけている。特に注目すべきは、LiveBench、LiveCodeBench、Chatbot Arenaという3つの主要ベンチマークでの評価結果だ。LiveBenchのグローバル平均スコアにおいて、o1-previewは66.02を記録し、2位のClaude 3.5 Sonnet(59.80)を大きく引き離している。特筆すべきは、推論平均で68.00、数学平均で62.92、データ分析平均で63.97という高スコアを達成した点だ。これらの数値は、o1-previewが複雑な推論や数学的問題解決、データ解析において卓越した能力を持つことを示唆するもの。
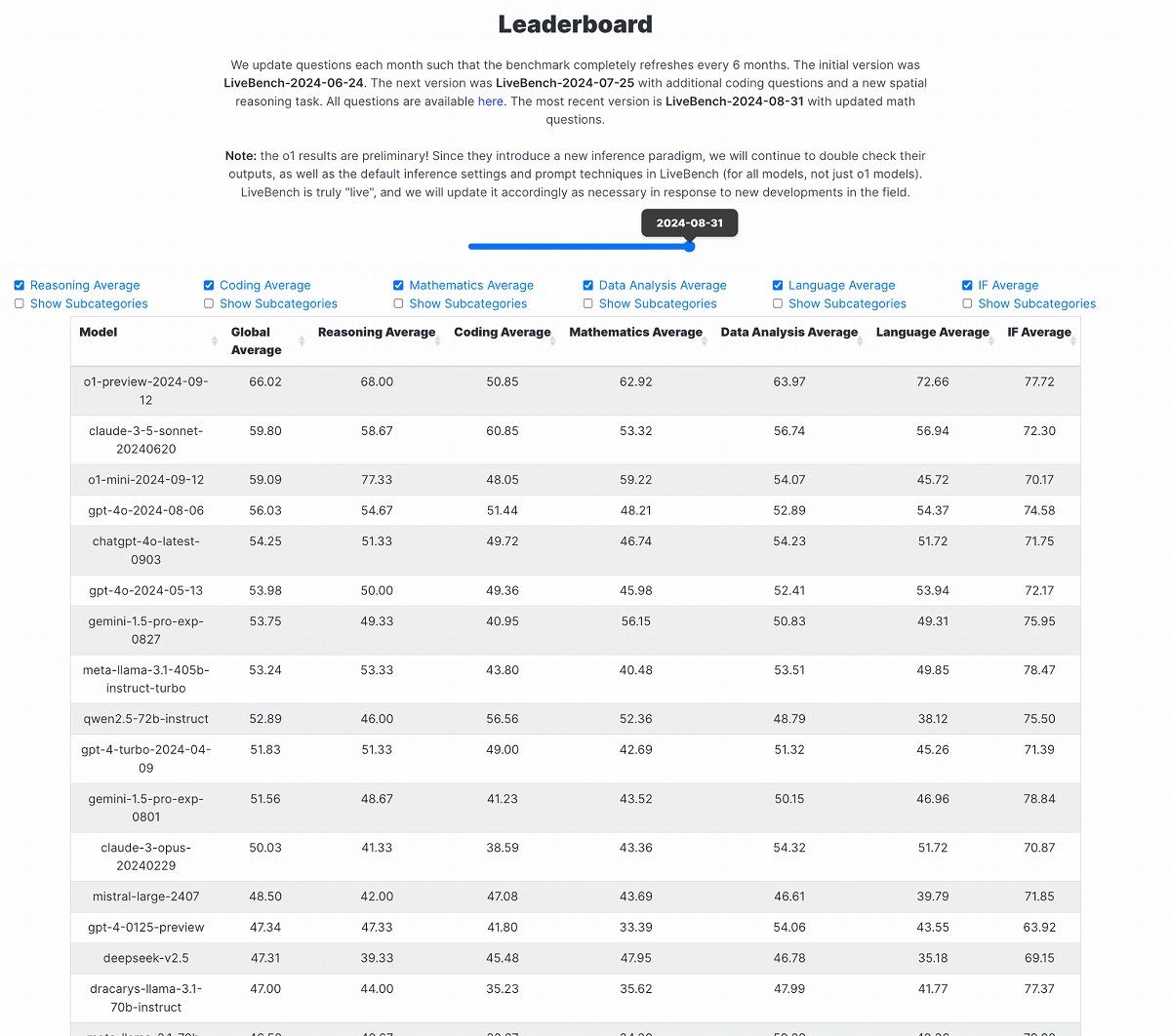
(出典:LiveBench)
一方、o1-miniは、グローバル平均で59.09を記録しつつ、特に推論平均では77.33という驚異的なスコアを達成した。これはo1-previewのスコアをも上回る数値となる。o1-miniが特定のタスク、とりわけ推論能力を要する問題に特化していることを裏付けるものと言える。
コーディング課題に特化したLiveCodeBenchでの評価も目を見張るものがある。注目したいのは、o1-miniが総合スコアでo1-previewを凌駕している点だろう。o1-miniはPass@1(1回目の試行で成功した割合)で73.1%を記録し、2位のo1-preview(57.3%)を大きく引き離しているのだ。難易度別の成績を見ると、o1-miniはEasy問題で94.3%、Medium問題で76.6%、Hard問題でも38.8%という高い成功率を記録。o1-miniがコーディングタスクにおいて、幅広い難易度に対応できる柔軟性を持っていることを示唆する数値だ。
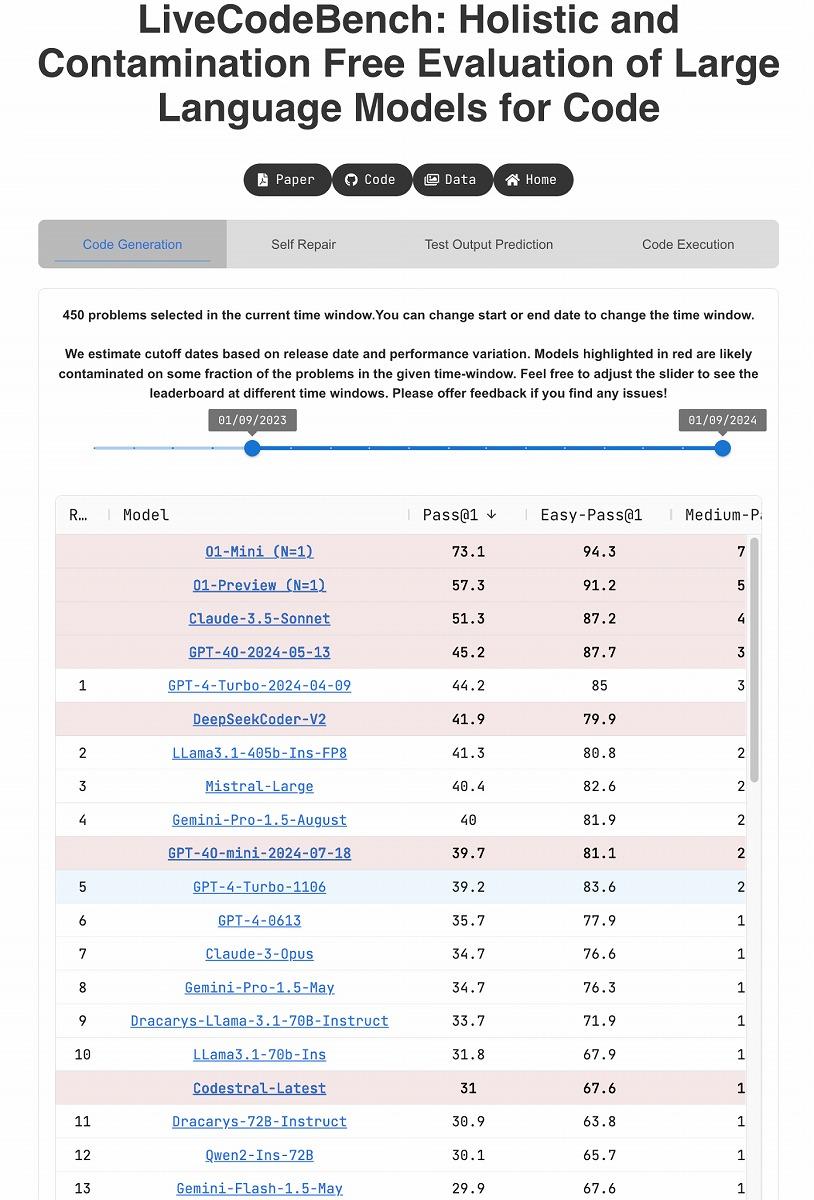
(出典:LiveCodeBench)
Chatbot Arenaのリーダーボードでも、o1-previewが1位を獲得。アリーナスコア1355、95%信頼区間+12/-11を記録し、2位のChatGPT-4.0-latest(1335)を上回る。o1-miniも1324のスコアで3位につけており、OpenAIのモデルが上位を独占する形となった。
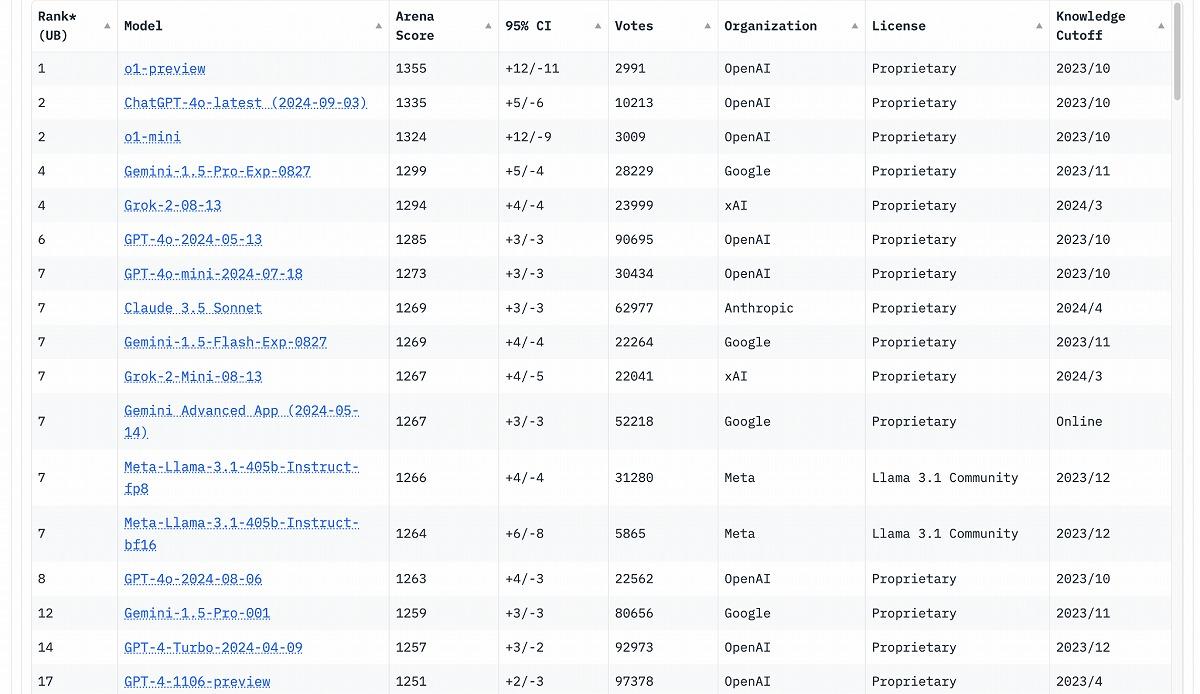
(出典:lmarena)
これらの結果は、o1シリーズが単なる進化版GPTモデルではなく、まったく新しいアプローチで開発された次世代AIモデルであることを裏付けるものと言えるだろう。 【次ページ】活用が期待される「ある分野」
AI・生成AIのおすすめコンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
AI・生成AIの関連コンテンツ
あなたの投稿
PR
PR
PR
