- 会員限定
- 2023/09/27 掲載
【文系でもわかる】ChatGPTのキモ「Transformer」「Attention」のしくみ
第1回は、さまざまなタスクをこなす万能型ジェネレーティブAIツール「ChatGPT」の性能の鍵を握る「トークン長(GPTが文脈を意識できる過去の単語数)」やGPTの歴史的経緯について解説しました。第2回はGPTを支える自然言語処理 の分野で使用される深層学習モデル「Transformer」とその根幹となる「Attention機構(そのタスクにおいてどの単語の重要度が高く、注目すべきか決める仕組み)」についてです。TransformerとAttention機構の仕組みを定性的に把握し、それを踏まえてGPTの能力と可能性について考察したいと思います。テクノロジー領域に明るくない人でもわかる記事を目指します。
2023年春、ChatGPTやLLMの進歩に衝撃を受ける。新しい技術を非専門家向けにも分かりやすく説明するのが得意。最近は勤務先の事業であるAMR(自律走行搬送ロボット)とLLMを融合したビジネスに興味。大学時代は人工知能系の研究室に所属、世界コンピュータ将棋選手権やACM-ICPCにも参加。

(Photo:Ascannio/Shutterstock.com)
本稿の要点とは?
本稿で述べているのは、以下のような内容です。
・GPTが革命的なのはプロンプトによって多様な用途に使える汎用性があることだが、それはGPTが「自己回帰モデル」であることに起因する
・GPTのキーパーツ(深層学習の部品)の「Transformer」の出自は「翻訳システム」だが、単語の意味や文法構造を解析する能力を持つ画期的な部品なので翻訳以外の用途にも利用が拡がった
・「Transformer」は深層学習モデルなので、その内部動作としては「言葉」のような「記号的」なデータではなく「数値」計算となり、「単語の列」である元データを「数値の列」に置き換えた「Attention」と呼ばれるデータが用いられる
・なぜ「Attention(=注意)」と呼ぶかというと、文や文章の「意味」をすべて「単語同士の関係」に帰着して表現したデータだからである
・文の意味解析という問題をはじめ、「翻訳」や「質問応答」といった一見異なるタスクに思われる問題を1つの深層学習モデルで扱えるという汎用性が、Transformer/Attentionの前提「すべての意味的な情報は単語同士の関係で表現できる」といったシンプルな原理によって実現されており、それが技術的なブレークスルーとなった
・これらの技術に早くからビジネス上のポテンシャルを見出し、リスクを取って財務的なコミットメントを継続したOpenAI社の経営は空前のイノベーションマネジメントである
・GPTのキーパーツ(深層学習の部品)の「Transformer」の出自は「翻訳システム」だが、単語の意味や文法構造を解析する能力を持つ画期的な部品なので翻訳以外の用途にも利用が拡がった
・「Transformer」は深層学習モデルなので、その内部動作としては「言葉」のような「記号的」なデータではなく「数値」計算となり、「単語の列」である元データを「数値の列」に置き換えた「Attention」と呼ばれるデータが用いられる
・なぜ「Attention(=注意)」と呼ぶかというと、文や文章の「意味」をすべて「単語同士の関係」に帰着して表現したデータだからである
・文の意味解析という問題をはじめ、「翻訳」や「質問応答」といった一見異なるタスクに思われる問題を1つの深層学習モデルで扱えるという汎用性が、Transformer/Attentionの前提「すべての意味的な情報は単語同士の関係で表現できる」といったシンプルな原理によって実現されており、それが技術的なブレークスルーとなった
・これらの技術に早くからビジネス上のポテンシャルを見出し、リスクを取って財務的なコミットメントを継続したOpenAI社の経営は空前のイノベーションマネジメントである
GPTの入出力をじっくり解説
本節では、ChatGPTの裏で動いているGPTという深層学習モデルをざっくり理解するため、「GPTの入出力」に注目します(一般的なコツとして、プログラムや機械学習モデルをざっくり理解したいときは、それが「何を入力して何を出力するのか」に着目するのが良いと筆者は考えています)。早速ですが、「Transformer」を構成するGPT(の最初のGPT-1)の構造をみてみましょう。
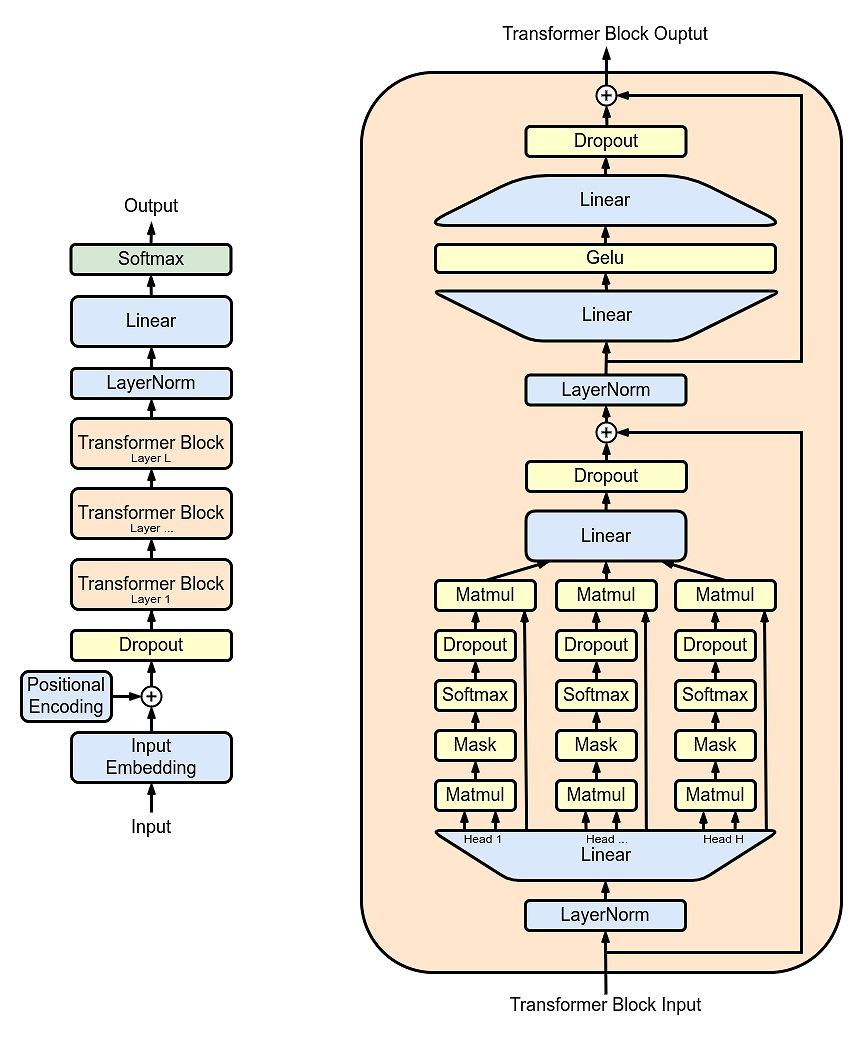
(出典:WikipediaのGPTのページ)
図の左側がGPTの全体の構造を表しており、そのなかで「Transformer Block」と書かれている部分を拡大したものが図の右側の構造です。Transformerの詳細に立ち入る前に、いったんGPTの全体(図の左側)の動きについて説明しましょう。
図の左の部分に、「Input」と「Output」があるように、この構造は下から入力し、上から出力が得られます。
入力とは具体的には、「直前のトークン(GPTが文脈を意識する単語)」です。トークンだと分かりにくいので、ひとまず単語だと思ってしまいましょう。
出力の方は、「次の単語」です。
例として、あなたの「Are you GPT?」という質問に対して、GPTが「Yes, I am.」と文を出力した場合の動作は以下のようになります。
Input:「Are | you | GPT | ? | (発話完了)」(5トークン)
発話を終えたことを示す特別なマークとして「(発話完了)」という1トークンを使用しているところがミソです。
以降では説明のため、トークン数の上限を5としましょう。
GPTの動作1回目
Input:「Are | you | GPT | ? | (発話完了)」(5トークン)
Output:「Yes」
GPTの動作2回目
Input:「you | GPT | ? | (発話完了) | Yes」(5トークン)
Output:「,」
GPTの動作3回目
Input:「GPT | ? | (発話完了) | Yes | ,」(5トークン)
Output:「I」
GPTの動作4回目
Input:「? | (発話完了) | Yes | , | I」(5トークン)
Output:「am」
GPTの動作5回目
Input:「(発話完了) | Yes | , | I | am」(5トークン)
Output:「.」
GPTの動作6回目
Input:「Yes | , | I | am| .」(5トークン)
Output:「(発話完了)」
発話を終えたことを示す特別なマークとして「(発話完了)」という1トークンを使用しているところがミソです。
以降では説明のため、トークン数の上限を5としましょう。
GPTの動作1回目
Input:「Are | you | GPT | ? | (発話完了)」(5トークン)
Output:「Yes」
GPTの動作2回目
Input:「you | GPT | ? | (発話完了) | Yes」(5トークン)
Output:「,」
GPTの動作3回目
Input:「GPT | ? | (発話完了) | Yes | ,」(5トークン)
Output:「I」
GPTの動作4回目
Input:「? | (発話完了) | Yes | , | I」(5トークン)
Output:「am」
GPTの動作5回目
Input:「(発話完了) | Yes | , | I | am」(5トークン)
Output:「.」
GPTの動作6回目
Input:「Yes | , | I | am| .」(5トークン)
Output:「(発話完了)」
このように、1つの発話を出力するまでにGPTを6回動作させました。最後の(発話完了)トークンが出力されたことで、ChatGPTのWebアプリケーションが、画面上にGPTの出力した文を表示し、ユーザーであるあなたに次の発話を促すようブラウザ上の入力エリアでカーソルを点滅させます。
この例により、前回の記事で述べた、GPTが応答を返す際に「文脈」を考慮してはいるものの、それが何か「情報が圧縮された塊」のようなものではなく単に「直前のトークン列」をまるっと入力として用いているに過ぎないのだ、といった話がより具体的にイメージしていだけたのではないかと思います。
さて、このように、GPT自身が出力したトークンを前のトークン列につなげて次の入力として用いることで逐次的に(順々に)、次々にトークンを生成して文や文章を紡いでいくモデルを「自己回帰モデル」と呼びます。 【次ページ】ChatGPTの「Transformer」「Attention」をわかりやすく解説
システム開発総論のおすすめコンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
あなたの投稿
PR
PR
PR
