- 会員限定
- 2024/09/01 掲載
プリンストン大調査で判明、AI選定を誤らせる「ベンチマーク」の大問題
生成AI市場では、単一の大規模言語モデルではなく、複数のモデルで構成されるAIエージェントの活用を試みる動きが活発化している。単一モデルでは難しいWebタスクやコーディングタスクなどの自動化が進められているのだ。これに伴い、AIエージェント用のベンチマークも続々と登場し、注目を集めている。しかし、AIエージェントやそもそものLLM、AIモデルのベンチマークにはさまざまな問題が内在するとの指摘もなされている。どのような問題があるのか、プリンストン大学の研究チームによる分析を紹介しよう。
英大学院修了後、RPA企業に勤務。大手通信社シンガポール支局で経済・テクノロジーの取材・執筆を担当。その後、Livit Singaporeでクライアント企業のメディア戦略とコンテンツ制作を支援(主にドローン/AI領域)。2026年2月、シンガポールで「SimplyPNG」を設立し、AI画像編集のモデル運用とGPUコスト最適化を手がける。主にEC向け画像処理ワークフローの設計・運用自動化に注力。

(Photo/Shutterstock.com)
AIエージェントとは?
AIエージェントは、人工知能(AI)技術の中でも特に注目を集める分野の1つだ。従来のAIシステムと比較して、より複雑な環境で自律的に行動し、目標を追求する能力を持つ。プリンストン大学の研究者らによると、AIエージェントは「環境を認識し、その環境に対して行動を起こす存在」として定義される。AIエージェントの特徴は、単なる言語モデルとは異なり、複数のタスクを連続して実行できる点にある。たとえば、Webブラウジングやプログラミング、ツールの使用など、より実世界に近い複雑なタスクを遂行できる。さらに、AIエージェントは自然言語での指示を理解し、ユーザーに代わって自律的に行動することが可能だ。
エージェントベースのアプリケーションも増えつつある。たとえば、Webタスクを自動化するZeta Labsの「Jace」。ユーザーとチャットする大規模言語モデル(LLM)とWebタスクを遂行するLLMで構成されるエージェントシステムで、旅行の予約や支払いなどを遂行する能力を持っている。このほかにも、コード生成、デバッグ、レビュー、ドキュメント生成などをこなすソフトウェアAIエージェント「SWE-agent」など、コーディング分野でもさまざまなエージェントが登場している。
この状況下、単一のLLMではなく、AIエージェントのパフォーマンスを評価しようという動きが活発化しており、エージェント用のベンチマークテストの開発が加速の様相だ。さまざまなエージェント用のベンチマークが登場しており、エージェントベースのアプリケーション開発などで参考にされるケースも増えている。
(出典:プリンストン大学研究レポート)
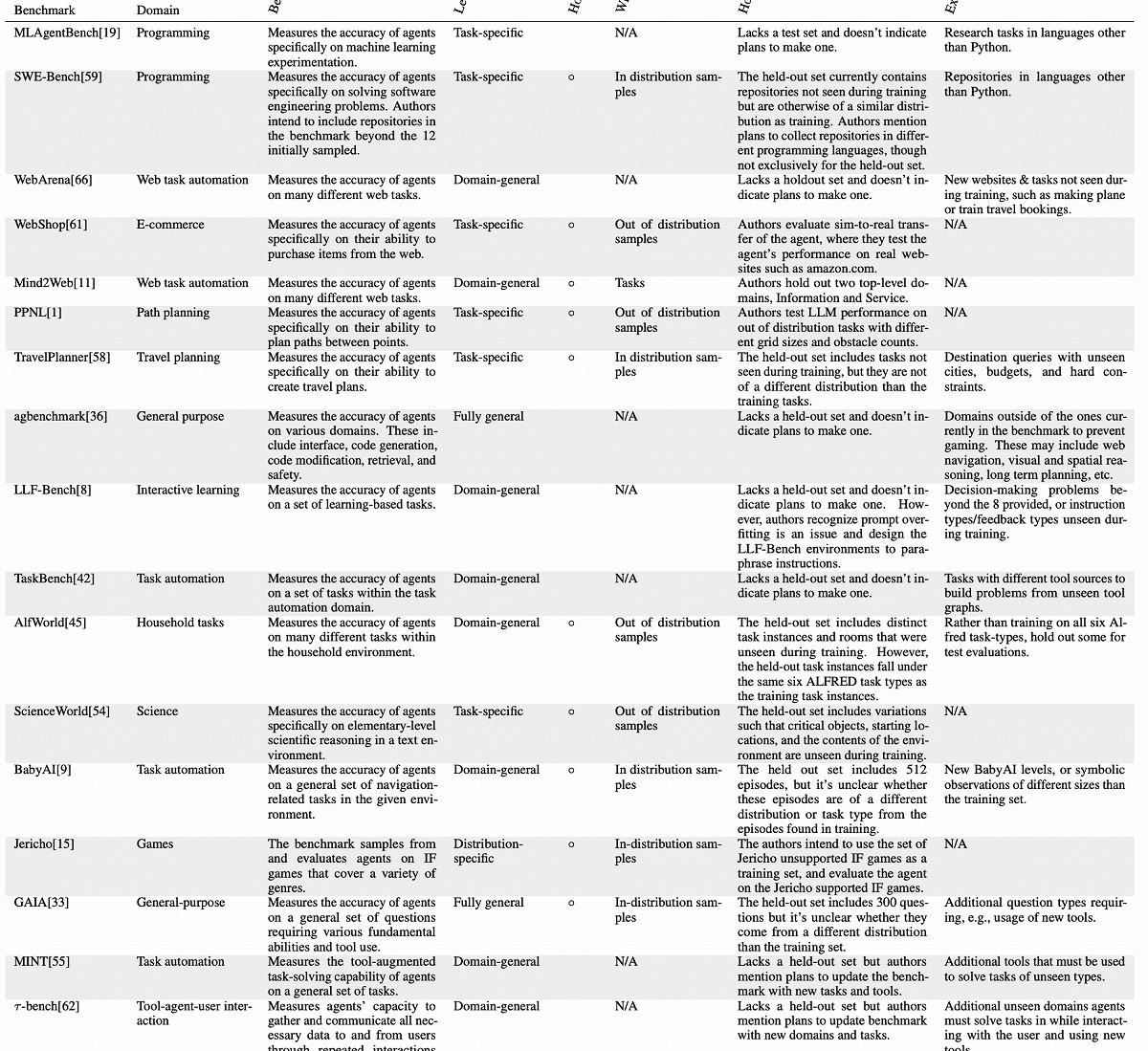
一方、プリンストン大学の研究者らによる分析では、エージェント用のベンチマークには多くの問題が内在しており、それを参考にした場合、予期せぬ問題に直面する可能性があることが判明した。
AIエージェントのベンチマークに内在する課題
プリンストン大学の研究チームは、現在のAIエージェントのベンチマークと評価手法に重大な欠陥があることを指摘している。最も深刻な問題の1つは、精度のみに焦点を当てた評価方法だ。研究チームによると、これらのベンチマークではコストが考慮されておらず、ベンチマークが示す精度のみでエージェントを選ぶと、コストが跳ね上がるリスクを負うことになるという。
単一LLMのコーディング能力評価でも使用されるHumanEvalベンチマークにおいて、同程度の精度を持つエージェント間でもコストが大きく異なることが明らかになったのだ。たとえば、Reflexionエージェントと比較して、LATS(Language Agent Tree Search)エージェントは16倍以上のコストがかかる。
ここでReflexionエージェントとLATSエージェントについて簡単に説明しておきたい。Reflexionエージェントは、言語強化学習を用いて自己反省と改善を行うAIエージェントだ。失敗したタスクに対して「反省」を生成し、その反省を基に再度タスクに挑戦する能力を持つ。一方、LATSエージェントは、言語モデルの推論能力を活用して、問題解決のための行動を選択するエージェント。ツリー探索アルゴリズムを用いて、最適な行動系列を見つけ出す。
(出典:プリンストン大学研究レポート)
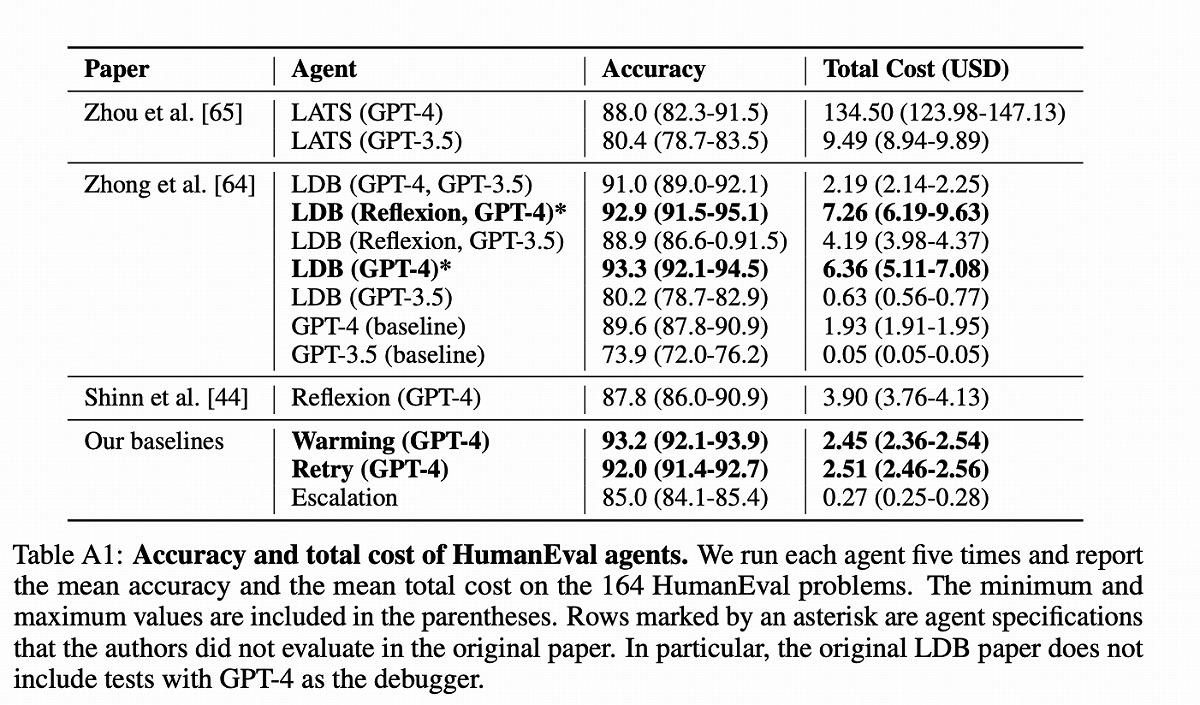
具体的な数字を見ると、エージェントではない単一のGPT-4を使用した場合は、平均1.93ドルのコストで89.6%の精度を達成できる。
一方、複雑なエージェントアーキテクチャを採用したLATSは、134.50ドルものコストがかかった一方で、精度は88.0%だった。70倍近いコスト差があるにもかかわらず、精度が低下してしまったケースとなる。
この調査結果を踏まえ、研究チームは、精度だけでなくコストも考慮に入れることの重要性を強調している。
実際に研究チームは、このような最適化を設計・実装し、精度を維持しながらコストを大幅に削減できる可能性を示した。その1つ「Warming」戦略は、HumanEvalで93.2%の精度を2.45ドルで達成、LATSと比較しても同等以上の精度を1/55以下のコストで実現した計算となる。
Warming戦略とは、初回の試行で温度(ランダム性)をゼロに設定。その後の試行で徐々に温度を上げていく(Warming)。2回目と3回目は0.3、4回目と5回目は0.5といった具合だ。
モデルのランダム性を高めると、斬新なアイデアを生み出す可能性が高くなる。上げ過ぎると一貫性を失ってしまうリスクを伴うが、バランスを取りつつ、ランダム性を活用できれば、袋小路に入る可能性を下げ、クリエイティブな回答生成が可能になる。
このWarming戦略を使うと、GPT-4単体(89.6%)に比べ、4ポイントほど精度を高めることができ、かつコストを2.45ドルに抑えられる。 【次ページ】コスト「以外」のさまざまな問題
AI・生成AIのおすすめコンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
AI・生成AIの関連コンテンツ
あなたの投稿
PR
PR
PR
