ビッグデータ3つのV、ポジショニングマップで理解するビッグデータ活用
- ありがとうございます!
- いいね!した記事一覧をみる
会員になると、いいね!でマイページに保存できます。
ここにきて「ビッグデータ」という言葉が巷でよく聞かれるようになった。ビッグデータとは、文字通り「巨大なデータ」という意味であるが、既存データの90%は、この2年以内に生成されたものというから、いかにデータが爆発的に増え続けているのか分かるだろう。いまや世界中で2.5EB(エクサバイト)ものデータが日々生成され、ネットワーク上に飛び交っている状況だ。この莫大な情報をいかにビジネスに活用し、新たなビジネス価値を生み出すのか、今後それが企業競争力の向上の要になる。
ビッグデータの特性を示す3つの“V”
そもそもビッグデータとは具体的にどのようなデータのことだろうか? 見解の相違はあるが、各種機器からのセンサによって吐き出されるデータや、金融市場のような連続するデータであったり、ブログ、TwitterやFacebookなどのソーシャルメディアに掲載された投稿、ネット上に保存された高解像度のデジタル写真・ビデオストリーム、オンライン購入の処理レコードの情報などなど、実に多種多様なソースから生成される。このように適用範囲の広いビッグデータだが、Samarter Planetの重要な要素としてビッグデータに早くから取り組んでいたIBMによれば、その大きな特性として3つの“V”が挙げられるという(図1)。
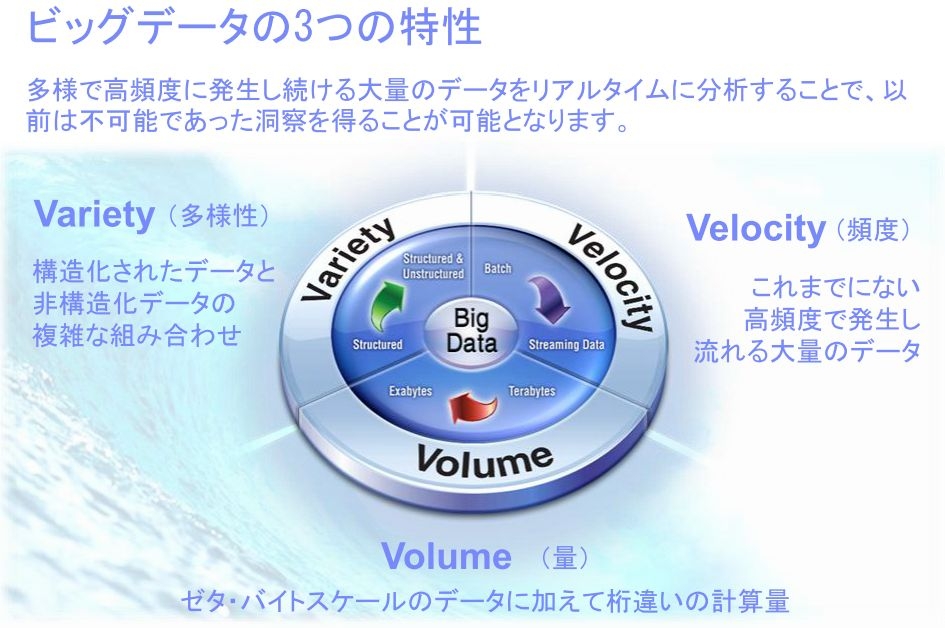
(出典:日本アイ・ビー・エム,2011)
1つめは「Variety」(多様性)のVだ。ビッグデータは必ずしも整形された「構造化データ」であるとは限らない。テキスト、音声、ビデオ、ストリームなど、リレーショナルデータベースに保存されていない種類の「非構造化データ」も多く存在する。ビッグデータは、構造化されたデータと非構造化データを包含したものである。
2つめは「Velocity」(頻度)のVだ。これはたとえば、ストリーミングデータに代表されるように、これまでにないぐらい高頻度で発生し、ネットに流れる大量の変動するデータが存在しているということを意味する。ほかにも、Twitterなど、膨大な数のつぶやきが非常に短い時間の中で発信されているのも、ビッグデータの「頻度」を示す分かりやすい例だろう。
そして3つめが“ビッグ”データという名前が示す「Volume」(量)のVである。テラバイトからゼタバイト、エクサバイトへと圧倒的なスケールに加えて、これらを処理するために飛び抜けた超ハイパフォーマンスが求められていることを意味する。
そして現在、このビッグデータが次世代のビジネスシーンを大きく変革するきっかけになるものと捉え、現実のビジネスへ最大限に活用することで成長を続けている企業が現れている。膨大に増え続け、高頻度に発生する多様なビッグデータを収集するだけでなく、それぞれの特性に合わせてリアルタイムに分析し、従来まで分からなかった「新しい発見」「洞察」「将来の予測」などをビジネスにつなげようとしているわけだ。
ビッグデータに対するアプローチをポジショニングマップで考える
今すぐビジネス+IT会員に
ご登録ください。
すべて無料!今日から使える、
仕事に役立つ情報満載!
-
ここでしか見られない
2万本超のオリジナル記事・動画・資料が見放題!
-
完全無料
登録料・月額料なし、完全無料で使い放題!
-
トレンドを聞いて学ぶ
年間1000本超の厳選セミナーに参加し放題!
-
興味関心のみ厳選
トピック(タグ)をフォローして自動収集!
関連タグ
タグをフォローすると最新情報が表示されます





