湖(データレイク)にたまった水を“価値のある飲料水”に変えるには?
CTO対談:ビッグデータ活用を阻む“技術の壁”を乗り越えるための選択肢
- ありがとうございます!
- いいね!した記事一覧をみる
会員になると、いいね!でマイページに保存できます。
ビッグデータ活用を推進する企業が増えている。しかし、その道筋は容易ではない。企業がデータを価値あるものに変えていく作業は、様々な技術の壁が立ちはだかるからだ。データが業務やシステムごとに分断された状態では、複数のデータを同時に読み出し、効率的に分析することは難しい。この状態から知見を得るためには、大きな手間と膨大な時間がかかってしまうだろう。こうした課題を乗り越えるために、テラデータが推進しているのがベストオブブリード戦略だ。ここでは、データ分析のリーダーであるテラデータと「Apache Hadoop」ディストリビューションのベンダーであるMapR Technologies両社のCTOから話を聞き、戦略の狙いや企業のデータ活用メリットについて考えていく。
ビッグデータの基盤として存在感を増すHadoop。その理由とは?
すでに「ビッグデータ」は、今後の企業のビジネス展開を考えるうえで欠かすことのできないキーワードとなった。
特に注目したいのは、活用するデータが大きく広がっている点だ。これまでシステム上で管理してきた取引データに加え、「IoT(Internet of Things)」によって生み出される各種センサー類から発信される「計測データ」や「ログデータ」も当然のように使われるようになった。製品や機器にセンサーを組み込めば、予防保守サービスや新製品の開発に役立てることもできる。
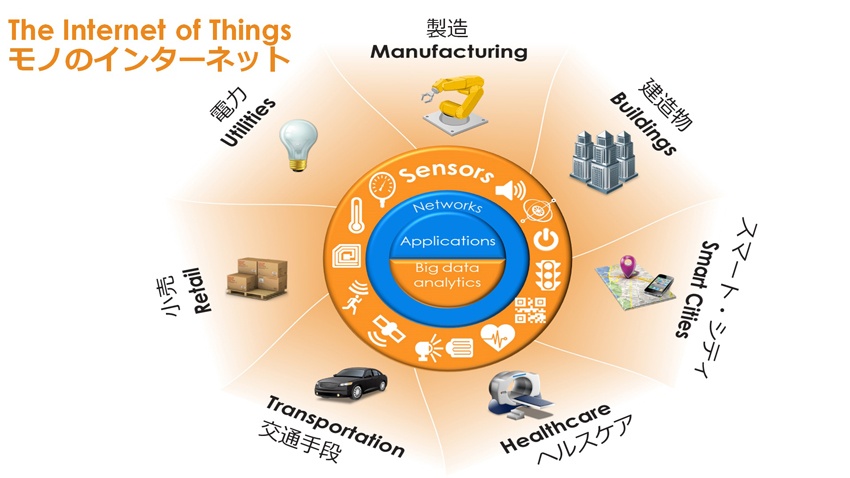
図1:モノのインターネット(IoT: Internet of Things)
データの広がりは「構造化データ」だけにとどまらない。電子メールやソーシャルメディアなどを通じてやりとりされる「テキストデータ」「音声データ」「動画データ」といった「多構造化データ」も多くの企業が活用するようになった。こうした情報を的確に分析できれば、顧客満足度の向上や売上の拡大、さらにはイノベーションを創出する可能性も高くなる。

テラデータ・コーポレーション
最高技術責任者(CTO)
スティーブン・ブロブスト氏
ただし、活用するデータの広がりは新たな課題も生む。それは多種多様なデータをどう管理していくかという問題だ。「大量のデータの中から、どれが貴重でどれが価値のないものかを判断するのは非常に困難です」とテラデータ・コーポレーションで最高技術責任者(CTO)を務めるスティーブン・ブロブスト氏は語る。
これまでのようにデータが業務やシステムごとに分断された状態では、複数のデータを同時に読み出し、分析することは難しい。この状態から知見を得るためには大きな手間と膨大な時間がかかってしまうためだ。
そこで最近では、システムで日々収集される膨大なデータを、巨大なリポジトリに、そのまま格納する「データレイク(Data Lakes:データの湖)」というコンセプトが大きな注目を集めている。
このデータレイクの実現に向け、重要な技術基盤と捉えられているのがHadoopだ。Hadoopは、多構造化データを含む大量のデータを溜め、分散並列処理するためのプラットフォームとして、日本でもすでに多くの企業で活用されている。このHadoopによるデータレイクは、サイロ化されたデータの解消にも役立ち、有効な分析用データ基盤となる。
「Hadoopならシステムによる容量制限から解放されます。つまり、これまで捨てざるを得なかったようなデータも含め、多種多様かつ膨大なデータを格納し、活用していくことができるわけです」とブロブスト氏は説明する。
特に注目したいのは、活用するデータが大きく広がっている点だ。これまでシステム上で管理してきた取引データに加え、「IoT(Internet of Things)」によって生み出される各種センサー類から発信される「計測データ」や「ログデータ」も当然のように使われるようになった。製品や機器にセンサーを組み込めば、予防保守サービスや新製品の開発に役立てることもできる。
データの広がりは「構造化データ」だけにとどまらない。電子メールやソーシャルメディアなどを通じてやりとりされる「テキストデータ」「音声データ」「動画データ」といった「多構造化データ」も多くの企業が活用するようになった。こうした情報を的確に分析できれば、顧客満足度の向上や売上の拡大、さらにはイノベーションを創出する可能性も高くなる。
最高技術責任者(CTO)
スティーブン・ブロブスト氏
そこで最近では、システムで日々収集される膨大なデータを、巨大なリポジトリに、そのまま格納する「データレイク(Data Lakes:データの湖)」というコンセプトが大きな注目を集めている。
このデータレイクの実現に向け、重要な技術基盤と捉えられているのがHadoopだ。Hadoopは、多構造化データを含む大量のデータを溜め、分散並列処理するためのプラットフォームとして、日本でもすでに多くの企業で活用されている。このHadoopによるデータレイクは、サイロ化されたデータの解消にも役立ち、有効な分析用データ基盤となる。
「Hadoopならシステムによる容量制限から解放されます。つまり、これまで捨てざるを得なかったようなデータも含め、多種多様かつ膨大なデータを格納し、活用していくことができるわけです」とブロブスト氏は説明する。
この記事の続き >>
・単一のベンダーが提供する技術には限界がある
・テラデータ×MapRの協業強化で、データ活用に高度な価値を提供
・単一のベンダーが提供する技術には限界がある
・テラデータ×MapRの協業強化で、データ活用に高度な価値を提供
今すぐビジネス+IT会員に
ご登録ください。
すべて無料!今日から使える、
仕事に役立つ情報満載!
-
ここでしか見られない
2万本超のオリジナル記事・動画・資料が見放題!
-
完全無料
登録料・月額料なし、完全無料で使い放題!
-
トレンドを聞いて学ぶ
年間1000本超の厳選セミナーに参加し放題!
-
興味関心のみ厳選
トピック(タグ)をフォローして自動収集!
関連タグ
タグをフォローすると最新情報が表示されます

