- 会員限定
- 2019/10/04 掲載
「信用スコア」の仕組みを解説、実はAI技術よりも大切なことがある
データレンディングの現状と未来(前編)
AI技術を活用したスコアレンディングへの取り組みがメディアなどで紹介され、新たなビジネス機会として話題になっている。しかし、信用スコアリングによる自動審査は日本でも1980年代後半から研究が始まり、1990年代以降には広く貸出判断に利用されるようになっている。そういった中で、海外での取り組みやAIブームの影響によって、最近の“信用スコアブーム”は誤解や過剰な期待が生まれている可能性もある。本稿では、20年以上にわたって信用スコアリングモデル構築に携わってきた筆者が信用スコアの正しい理解と活用のために最近のAIブームの背景や与信・審査分野でのこれまでの取り組み、スコアリング技術を活用するうえでの注意点や求められる事項について解説する。
20年以上に渡り、統計分析や機械学習、AI導入等の多数のデータ活用コンサルティング業務に従事。同時に数理モデル構築やディシジョンマネジメント領域でのソフトウエア開発、新規事業やAnalytics組織の立上げなどの経験を通じて数多くの顧客企業のビジネスを改善。リスク管理、不正検知、与信管理、債権回収、内部統制・内部監査、マーケティングなどの幅広い分野でAnalyticsプロジェクトをリードしている。
定義が難しい「AI」
インターネットの普及とITの進展により、ビジネスで利用できるデータが爆発的に増えたことで、最近では“データは重要な経営資源”と言われるようになった。実際にGAFA(グーグル、アップル、フェイスブック、アマゾン)やBATH(バイドゥ、アリババ、テンセント、ファーウェイ)などのプラットフォーマーと言われる、膨大なデータを独占する事業者の影響力が大きくなっている。
そういった流れのなかで、第3次ブームと言われているAI(人工知能)技術に注目が集まっているのはご認識の通りである。
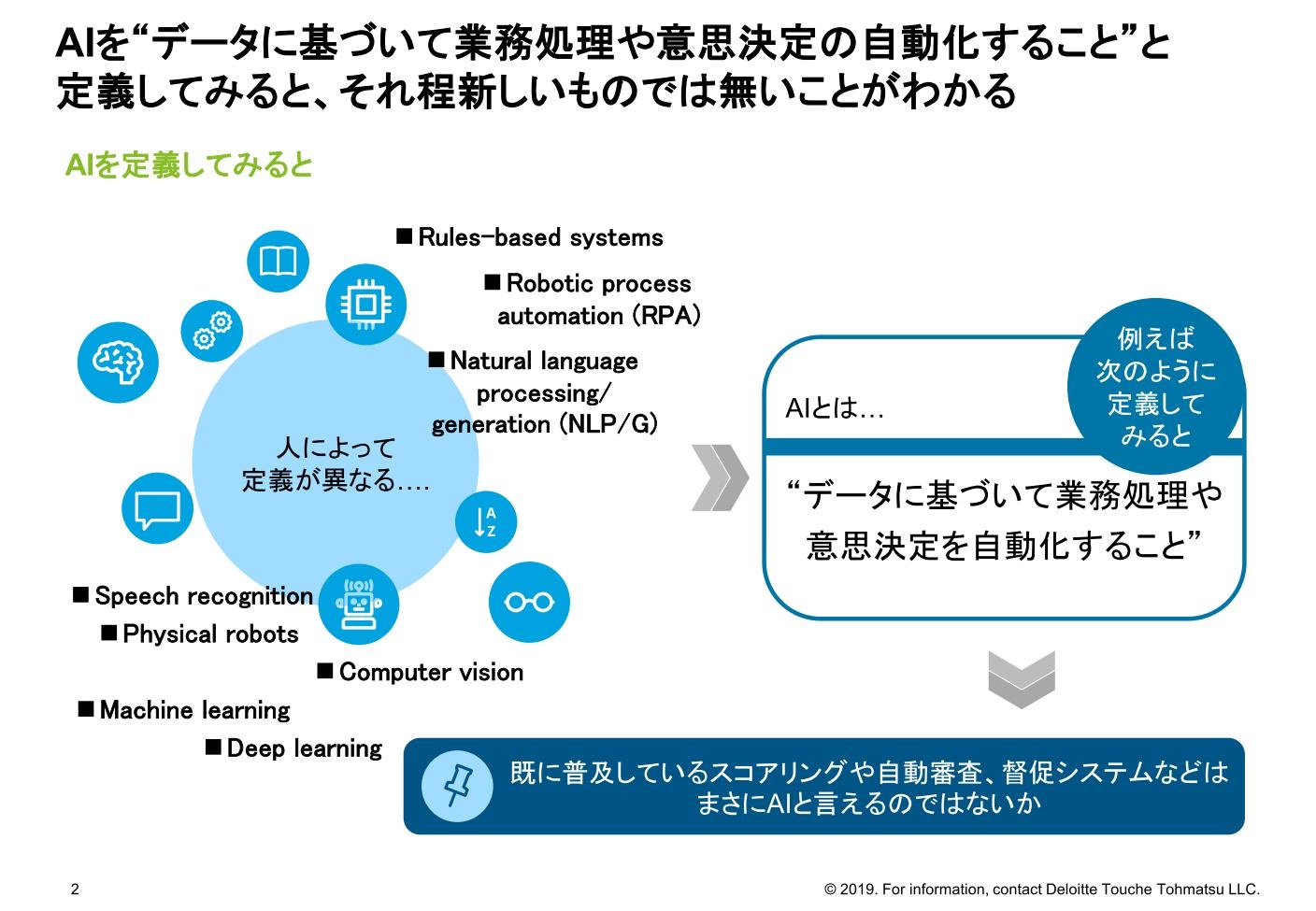
しかし、AIという用語がさまざまな場面で用いられていることもあり、AIの定義が難しくなっている。人によっても理解や捉え方が異なり、広くデータ活用一般のことをAIと呼ぶこともあれば、統計モデルの活用を指す場合や、さらにその中の機械学習(マシンラーニング)を指す場合、またさらに限定して深層学習(ディープラーニング)をAIとしているケースもある。
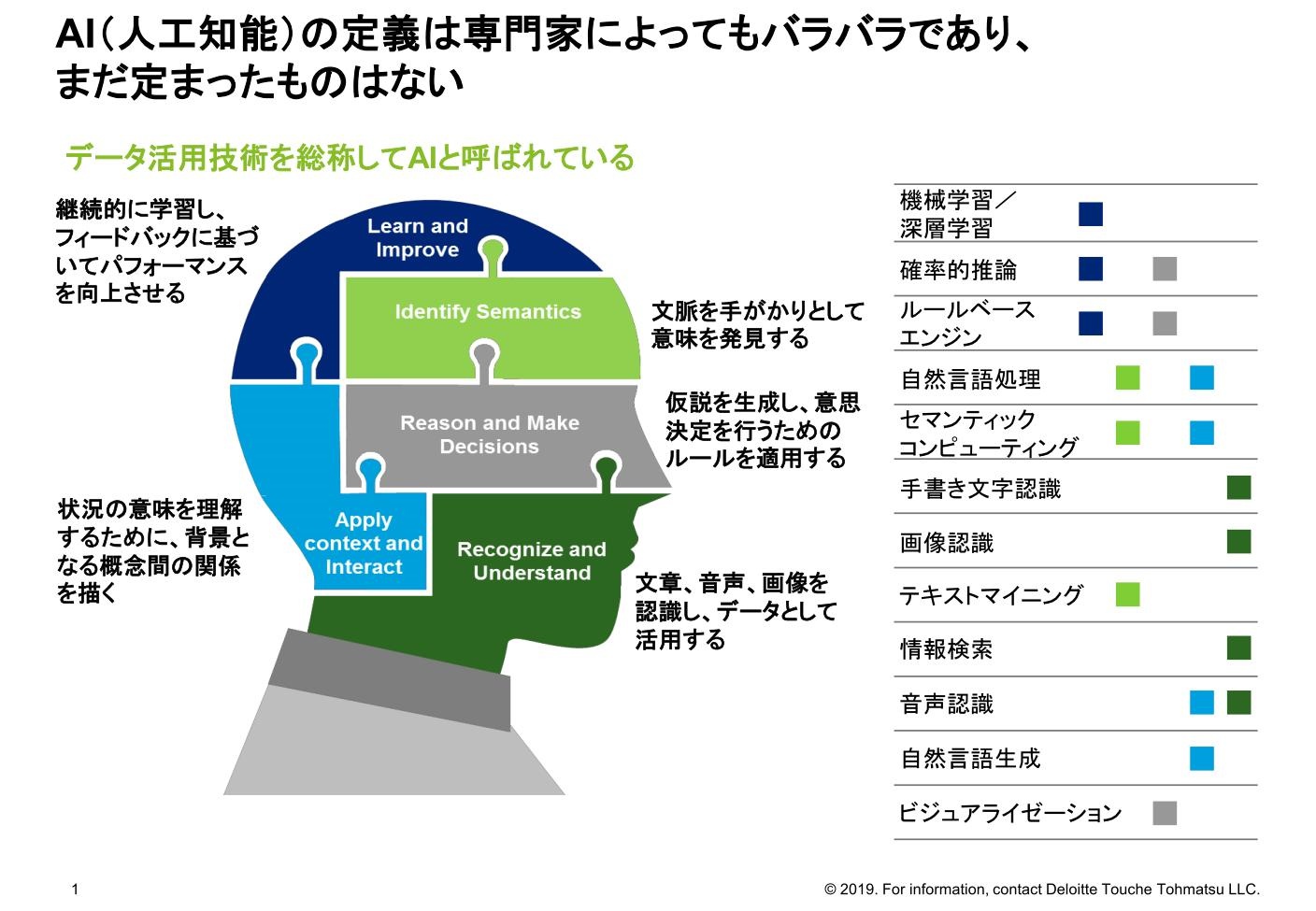
実際には機械学習は決して新しいものではなく、最近話題の深層学習のベースになっているニューラルネットワーク技術も1950年代にその理論が構築されたと言われている。
ロジスティック回帰などの統計モデルや決定木といった機械学習モデルはすでに広い分野で活用されていたため、以前から関連した仕事をしていた人の中には、昨今のAIブームにやや違和感を持たれた方もいるのではないだろうか。
今回のブームでは、ニューラルネットワークを応用した深層学習モデルによって、それまで活用が進んでいなかった“画像や音声データ“がビジネスレベルで利用できる精度で認識できるようになった点が画期的であったと言える。
逆に言うと、以前から使われていた数値データの利用技術については、それほど大きな進展があった訳ではないが、同じAIブームの中で、データを活用した業務の高度化が一般的にAIと呼ばれているようである。
信用スコアでは優位性がない深層学習
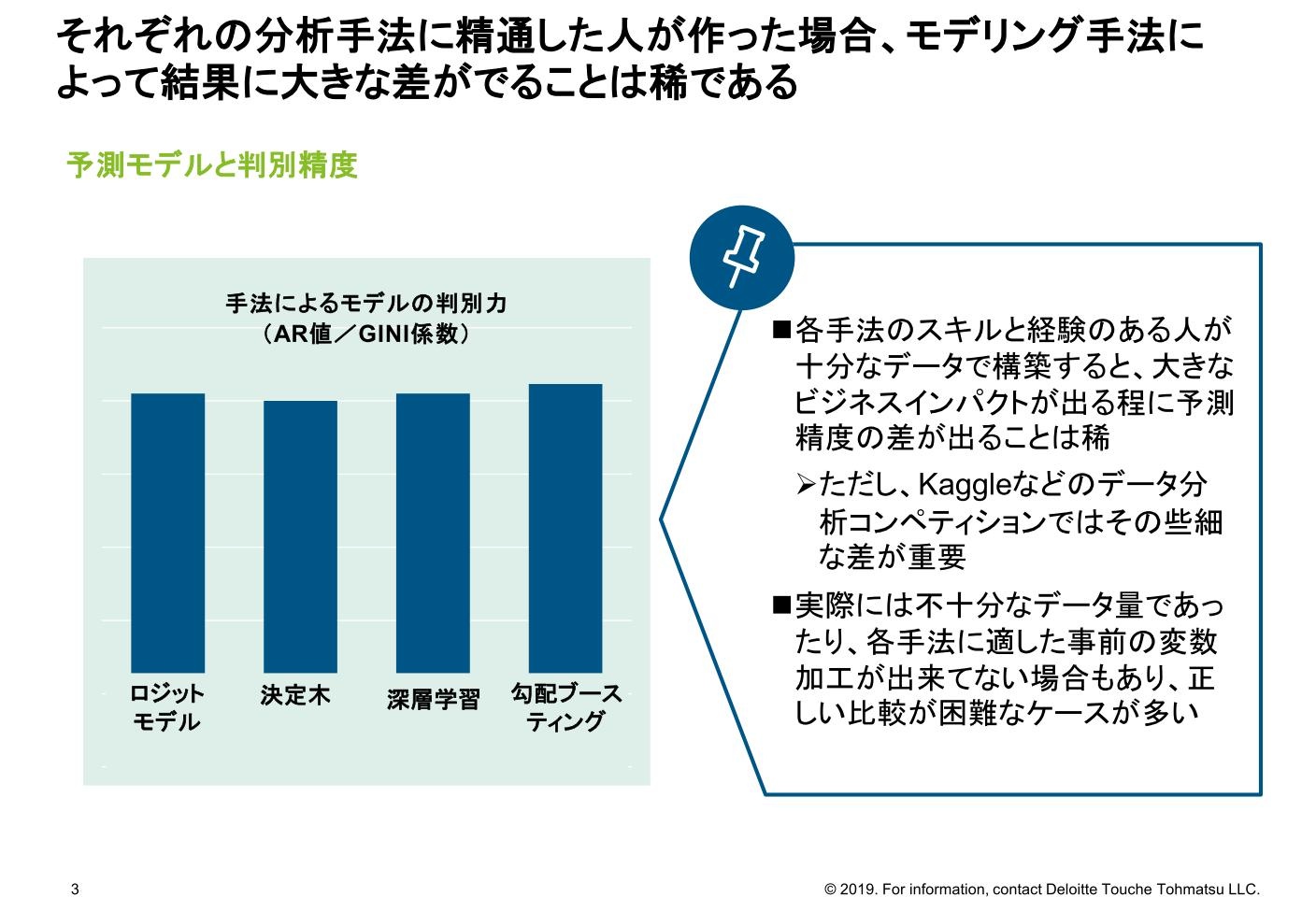
AIブームのきっかけになった“深層学習”が話題になることが多いが、信用スコアリングモデルの分野では他の手法と比較して優位性がないことをご存じだろうか?実はこの分野では、各手法に精通した人が十分なデータを使ってモデルを構築すれば、モデリング手法によって予測精度に大きな違いが出ることはまれである。
予測モデルの精度を示す指標であるジニ係数(AR値と同じ)で2から3ポイント程度の差が出る程度で、(後述するが)スコアだけで与信判断を行う訳ではないこともあり、予測精度の差が大きなビジネスインパクトになることはほぼない。
その一方で、深層学習はブラックボックスタイプのモデルであり、スコア結果の理由の説明が難しいため、あえて採用するメリットが少ない。
むしろ重要なのは、スコアモデルの要素となる信用リスクと関連の強いデータ項目をどれだけ利用できるかである。
たとえば、借入残高が同じ30万円前後のAさんとBさんがいたとする。その場合、借入残高だけを見ていても、貸倒リスクの違いははっきりしないが、“その人の使えるカードの枚数や限度額のうちどれだけ使っているか“という点に注目してデータを作成すると、高い予測精度のスコアモデルを構築することができる。
つまりは、モデリング手法よりも、“いかに有効な入力データ”を準備できるかがスコアの性能を左右するということだ。

【次ページ】海外と日本市場で何が違うのか
あなたの投稿
PR
PR
PR
