0
会員になると、いいね!でマイページに保存できます。
「今のビジネストレンドに対応していくためには、従来型のデータ管理とデータ処理ではもはや困難だ」。米ガートナーのジェイミー・ポプキン氏はそう指摘する。現在の企業において、ビッグデータに限らず、データ分析はもはや避けては通れない重要な取り組み課題の1つとなっている。では、従来のデータ処理とビッグデータ分析ではどのような点が異なるのだろうか。企業は、どのような技術を用いて、どのような体制で臨めば良いのか。
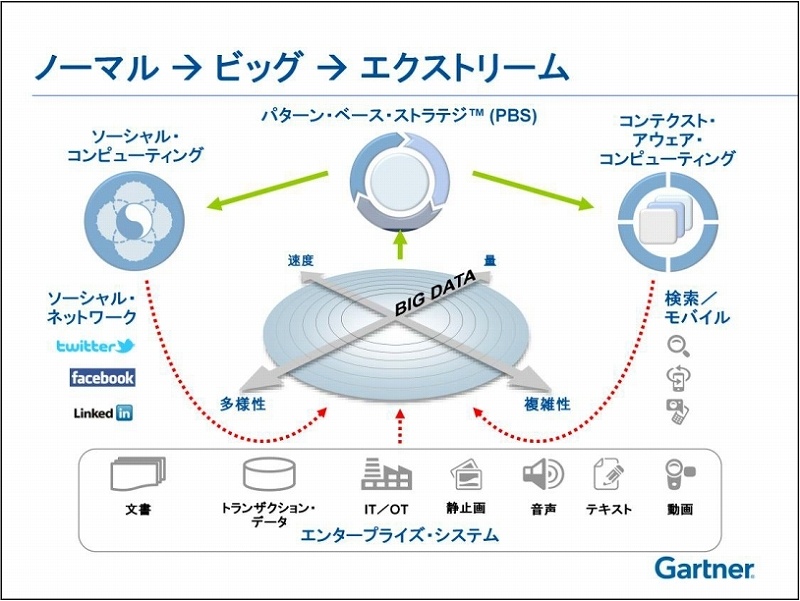
ビッグデータの分析は、エクストリームな情報管理の領域
ビッグデータを語る時、まず「量(Volume)」に注目が集まるが、それはあくまでも1つの側面に過ぎない。ストレージの低価格化は進み、プロセッサの処理能力もどんどん高くなってきている。量だけを考えるなら、取り扱いそのものはシンプルだ。
しかしビッグデータには他の要素がある。たとえばソーシャルネットワークやモバイルコンピューティング環境から得られるデータなど、データの速度(発生頻度)や多様性、複雑性は増している状況だ。これがまさにビッグデータの環境だと言える。
ガートナーが提唱する考え方に、パターン・ベース・ストラテジ(PBS)というものがある。マネジメントの観点からデータ群に対してマイニングをかけ、文字通りビジネスのパターンを見つけていくというものだ。ビジネス・インテリジェンス&情報活用サミット2012に登壇した米ガートナー リサーチ バイス プレジデントのジェイミー・ポプキン氏は、PBSには3つの要素があると説明する。
1つめが“Seek”で、パターンを探索するということだ。たとえば、将来的には市場に対して大きく影響を及ぼしうる事象を導き出すといったことである。
2つめが“Modeling”で、導き出したパターンの意義やインパクトを明らかにし、その特性を定量化することだ。いろいろな結果が考えられる中で、最も可能性が高いのはどのパターンなのかを明確にすることを目的とする。
そして3つめが“Adapt”、即ち適応で、導き出した新しいパターンに対して、企業としてどういうアクションを取るのかということだ。ビジネスの中でどう実践していくのかというパターンへの適用を推し進めていく。
「つまりビッグデータの分析は、さまざまな速度/サイズ/フォーマットで入ってくるデータをいち早く捉えてパターンを探索し、意味ある形にモデリングをして、ビジネスの中で実践に移していくということ。まさにエクストリームな(=過度な、極限の)情報管理の領域だ。」
ビッグデータ分析は、オープンソースソフトウェアの活用を視野に
ガートナーの調査によれば、データは毎年40%以上の成長率で増え続けるという。こうしたデータには、当然非構造型データも含まれ、より高度なデータ分析が必要となってくる。
たとえば小売業におけるビッグデータの活用例として、ポプキン氏は自身のネットショッピングにおける体験を挙げる。ポプキン氏が、ある通販サイトで花を買おうとしたところ、購入の一歩手前まで価格が分からない状態だったため、そのサイトを離れて別の通販サイトに移った。しかし、移った先の通販サイトでも同じような状態だった。そこで購入自体を放棄したのだが、15分後に最初に訪れたサイトから、“今再びサイトにアクセスしてもらえれば20%ディスカウントします”という内容のメールが送られてきた。
「バレンタインデーの1週間前で何千人という人がアクセスしていたと思われるが、そのサイトではクリックストリーム分析を行い、私が途中で購入手続きを止めたことを捉え、他社サイトと比較されているのかもしれないと考えて、わずか15分で20%ディスカウントのメールを送ってきた。非常にパワフルなビッグデータ分析の例だ。」
この例を受けてポプキン氏は、ビッグデータの量と複雑性が、分析そのものも複雑にしていると指摘する。Webサイト上でユーザーがどう振る舞うのかを知る必要があるし、ソーシャルメディア関連のデータも処理する必要がある。またデータウェアハウスに取り込む前にデータを選別する必要があるし、ビデオを検索するための動画検索エンジンの分類も必要だ。
さらにポプキン氏がより重要だと指摘するのは、分析モデルにおける、ある変化だ。一般的なデータ分析は、非常に洗練されたアルゴリズムを用い、少量のデータを使って正確な分析を行う。しかし、データ量が膨大になれば、適用するアルゴリズムは逆にもっとシンプルなものを使うことができるという。
「大量のデータには、シンプルなアルゴリズムを組み合わせたほうが、分析の精度が高くなる。」
またオープンソースソフトウェア(OSS)の採用も受け入れていく必要がある。現在OSSの世界においては、統計解析言語「R」を使用したデータ分析や統計的処理、大規模データを分散処理するためのソフトウェア開発基盤「Apache Hadoop」を使用したデータ処理フレームワークなど、幅広いプロジェクトが行われており、さらにはRed HatやClouderaというようなOSSに付加価値を与えるベンダも成長してきている。
「今はOSSだからといって問題にはならない時代。使わない手はない。」
【次ページ】従来のデータ処理とビッグデータ分析で異なる4つのポイント
関連タグ